Function
Ref. Model
I/O Data
SubAIMs
JSON MData
Profiles
Ref. Software
Conformance
Performance
1 Functions
The Context Capture (PGM‑CXC) AIM is the A‑User’s active perceptual interface to the spatial environment. It collects, fuses, and structures multimodal contextual information — including audio, visual, and spatial — and supports runtime reorientation under explicit Human or A‑User Control commands.
Context Capture provides initial Audio Scene Descriptors and Visual Scene Descriptors including object localisation, User gaze/gesture alignment, and spatial layout information, which are passed to Context Enhancement for further processing.
Context Capture may be directed by the Human through natural commands (e.g., “look at that corner”, “zoom there”, “follow that object”), which A‑User Control translates into perceptual redirection operations. These operations adjust Context Capture‘s capture configuration prior to any semantic interpretation.
Specific functionalities:
Multimodal Context Acquisition: The Context Capture AIM continuously captures audio, visual, and spatial data from the surrounding environment in a given Time Expression.
Audio and Visual Scene Descriptor Generation: The Context Capture AIM generates Audio Scene Descriptors and Visual Scene Descriptors describing object localisation, spatial layout, User gaze/gesture alignment, and other perceptual features of the environment.
Human‑Driven Perceptual Redirection: The Context Capture AIM supports perceptual redirection when instructed by the Human through A‑User Control (e.g., reorienting viewpoint, changing focus, zooming, following a referenced object or region).
Runtime Capture Reconfiguration: The Context Capture AIM dynamically reconfigures its capture parameters (e.g., direction, focus, zoom, sampling region) in response to perceptual redirection commands issued by A‑User Control.
Perceptual Grounding for Goal Acquisition: The Context Capture AIM provides perceptual descriptors that enable spatial grounding of Human expressions involving referenced objects or regions (e.g., “that corner”, “this object”, “over there”).
2 Reference Model
Figure 1 gives the Reference Model of the Context Capture (PGM‑CXC) AIM.
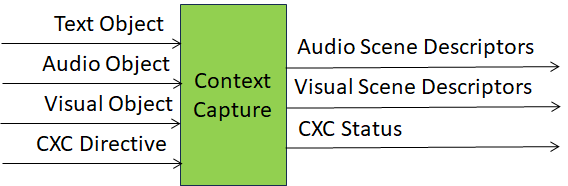
Figure 1 – The Reference Model of the Context Capture (PGM‑CXC) AIM
3 Input/Output Data
Table 1 gives the Input and Output Data of the Context Capture (PGM‑CXC) AIM.
Table 1 – Input and Output Data of the Context Capture (PGM‑CXC) AIM
| Input | Description |
|---|---|
| Text Object | User input expressed in structured text form, including written or transcribed utterances. |
| Audio Object | Captured audio signals from the scene, covering speech, environmental sounds, and paralinguistic cues. |
| Visual Object | Visual signals from the scene, encompassing gestures, facial expressions, and environmental imagery. |
| CXC Directive | Control instructions specifying modality prioritisation, acquisition parameters, or framing rules to guide the perceptual processing of an M‑Location. |
| Output | Description |
| Audio Scene Descriptors | Initial Audio Scene Descriptors produced by Context Capture, prior to Enhancement. |
| Visual Scene Descriptors | Initial Visual Scene Descriptors produced by Context Capture, prior to Enhancement. |
| CXC Status | Scene‑level metadata describing User presence, environmental conditions, and confidence measures for contextual framing. |
4 SubAIMs
4.1 Reference Model
Figure 2 depicts the Reference Architecture of the Context Capture (PGM‑CXC) Composite AIM.

Figure 2 – Reference Architecture of the Context Capture (PGM‑CXC) Composite AIM
4.2 Operation
The Context Capture (PGM‑CXC) AIM is activated by an A‑User Control CXC Directive and reports on execution by means of a CXC Status. The four input types are either passed through (Text Object) or processed by a dedicated SubAIM (3D Model, Audio, and Visual).
4.3 Functions of AI Modules
Table 2 specifies the Functions of the Context Capture (PGM‑CXC) SubAIMs.
Table 2 – Functions of the Context Capture (PGM‑CXC) SubAIMs
| SubAIM | Function |
|---|---|
| (pass through) | Passes Text Object directly to output without processing. |
| Audio Scene Description | Produces Audio Scene Descriptors from Audio Object input. |
| Visual Scene Description | Produces Visual Scene Descriptors from Visual Object input. |
4.4 I/O Data of AI Modules
Table 3 specifies the Input and Output Data of the Context Capture (PGM‑CXC) SubAIMs.
Table 3 – Input and Output Data of the Context Capture (PGM‑CXC) SubAIMs
| SubAIM | Receives | Produces |
|---|---|---|
| (pass through) | Text Object | Text Object |
| Audio Scene Description | Audio Object CXC Directive |
Audio Scene Descriptors CXC Status |
| Visual Scene Description | Visual Object CXC Directive |
Visual Scene Descriptors CXC Status |
4.5 AIMs and JSON Metadata
Table 4 provides the links to the AIM specifications and to the JSON schemas. AIM1 indicates the Composite AIM and AIM2 its SubAIMs.
Table 4 – AIMs and JSON Metadata
| AIM1 | AIM2 | Name | JSON |
|---|---|---|---|
| PGM-CXC | Context Capture | X | |
| OSD-ASD | Audio Scene Description | X | |
| OSD-VSD | Visual Scene Description | X |
5 JSON Metadata
https://schemas.mpai.community/PGM1/V1.0/AIMs/ContextCapture.json
6 Profiles
No Profiles.