| Function | Ref. Model | I/O Data | SubAIMs | JSON MData | Profiles | Ref. Software | Conformance | Performance |
1 Functions
The Audio Scene Enhancement (PGM-ASE) AIM performs interpretative enrichment of an audio scene captured by Context Capture, in order to derive additional, non‑perceptual audio properties relevant to spatial understanding, interaction, and user‑centric reasoning.
ASE operates on Audio CXE Directive received from A-User Control, Audio Scene Descriptors (ASD) received from Context Capture, and Audio Domain Response resulting from queries made to Domain Access and produces Audio CXE Status sent to A-User Control, Enhanced Audio Scene Descriptors sent to Prompt Creation and Audio Domain Request when querying Domain Access.
Enhanced Audio Scene Descriptors preserve the original perceptual semantics while augmenting them with derived and semantic information under directive control.
2. Reference Model
Figure 1 gives the of Audio Scene Enhancement (PGM-ASE) AIM Reference Model.

Figure 1 – The Reference Model of the Audio Scene Enhancement (PGM-ASE) AIM
3. Input/Output Data
Table 1 gives the Input/Output Data of the Audio Scene Enhancement (PGM-ASE) AIM.
Table 1 – Input/Output Data of the Audio Scene Enhancement (PGM-ASE) AIM
| Input | Description |
| Audio Scene Descriptors | Perceptual description of the audio scene produced by Context Capture. |
| Audio CXE Directive | Control directives specifying scope, depth, or policy constraints for audio enhancement. |
| Audio Domain Request | Domain‑specific knowledge supporting audio interpretation and semantic classification. |
| Output | Description |
| Enhanced Audio Scene Descriptors | Audio Scene Descriptors augmented with derived and semantic audio properties produced by ASE. |
| Audio CXE Status | Status information describing the execution and outcome of Audio Scene Enhancement processing. |
| Audio Domain Response | Response to Domain‑specific knowledge request. |
4. SubAIMs (informative)
4.1 Reference Model
An implementation of Audio Scene Enhancement (PGM-ASE) AIM may be based on the architecture of Figure 2.
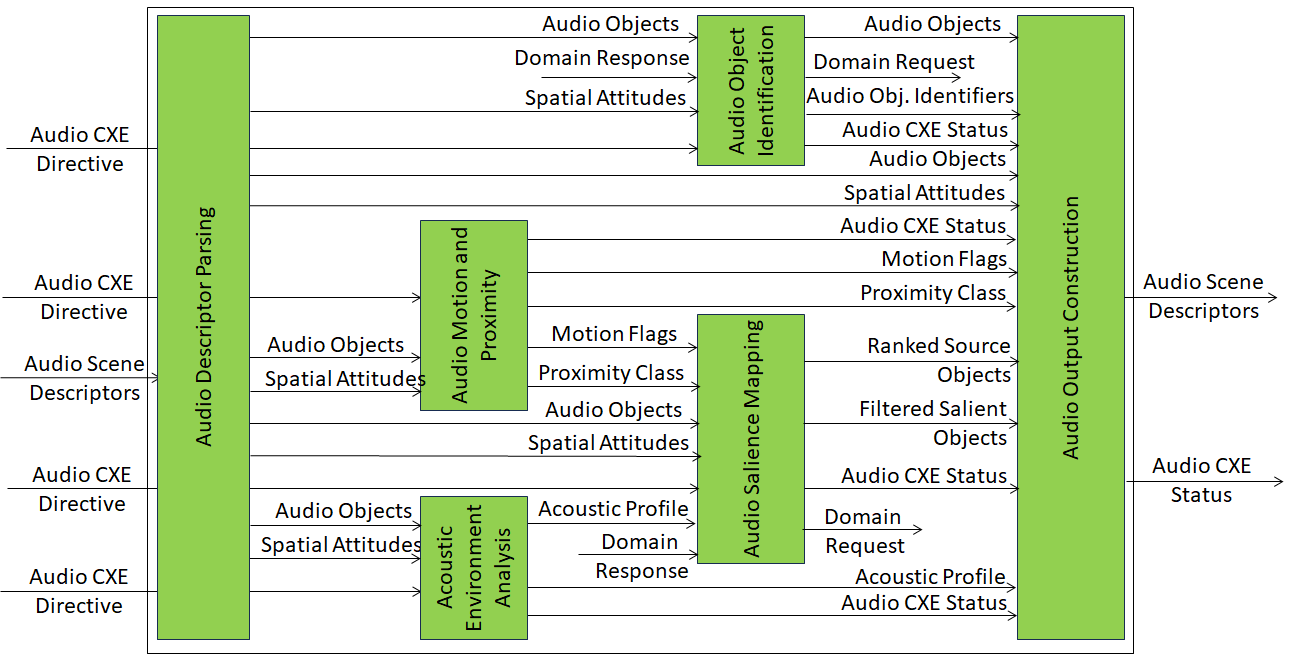
Figure 2 -Reference Model of the Composite Audio Scene Enhancement (PGM-ASE) AIM.
4.2 Operation
4.3 Functions of AI Modules
Table 2 specifies the Functions performed by PGM-ASP AIM’s SubAIMs in the current example.
Table 2 – Functions performed by Audio Scene Enhancement (PGM-ASE) AIM s SubAIMs
| SubAIM | Description |
|---|---|
| Audio Descriptor Parsing | Structures raw Audio Scene Descriptors into explicit Audio Objects and spatial attributes without semantic interpretation. |
| Audio Motion & Proximity Analysis | Detects temporal and spatial dynamics of audio objects by tracking their evolution in space and time. |
| Acoustic Environment Analysis | Characterises the acoustic conditions affecting audio objects using signal‑derived measures. |
| Audio Object Identification | Assigns semantic object type labels to audio objects using classification models and optional domain knowledge. |
| Audio Salience Mapping | Determines the relative relevance of audio objects with respect to user interaction and context. |
| Audio Output Construction | Aggregates perceptual and enriched evidence into Enhanced Audio Scene Descriptors and emits execution status. |
4.4 I/O Data of AI Modules
Table 3 specifies the Input/Output Data of the PGM-ASE AIM’s SubAIMs.
Table 2 – Functions performed by Audio Scene Enhancement (PGM-ASE) AIMs SubAIMs
| SubAIM | Input Data | Output Data |
|---|---|---|
| Audio Descriptor Parsing | Audio Scene Descriptors Audio CXE Directive |
Audio Objects Spatial Attitudes Audio CXE Status |
| Audio Motion & Proximity Analysis | Audio Objects Spatial Attitudes |
Motion Flags (e.g. stationary, moving) Proximity Class (e.g. near, mid, far) |
| Acoustic Environment Analysis | Audio Objects Spatial Attitudes |
Acoustic Profile (e.g. reverberation, ambient noise, spectral characteristics) |
| Audio Object Identification | Audio Objects Spatial Attitudes Domain Response |
Audio Object Type (e.g. speech, music, alarm) Type Confidence |
| Audio Salience Mapping | Motion Flags Proximity Class Acoustic Profile Audio Object Type Audio CXEDirective Domain Response |
Ranked Audio Objects Filtered Salient Audio Objects |
| Audio Output Construction | Audio Objects Spatial Attitudes Motion Flags Proximity Class Acoustic Profile Audio Object Type Salience Results |
Enhanced Audio Scene Descriptors (Enhanced ASD) Audio CXE Status |
4.5 AIMs and JSON Metadata
Table 4 provides the links to the AIM specifications and to the JSON syntaxes. AIM1 indicates the Composite AIM and AIM2 its SubAIMs.
Table 4 – AIMs and JSON Metadata
| AIM1 | AIM2 | Name | JSON |
| PGM-ASE | Audio Scene Enhancement | ||
| Audio Descriptor Parsing | |||
| Audio Motion & Proximity Analysis | |||
| Acoustic Environment Analysis | |||
| Audio Object Identification | |||
| Audio Salience Mapping | |||
| Audio Output Construction |
5. JSON Metadata
https://schemas.mpai.community/PGM1/V1.0/AIMs/AudioSceneEnhancement.json