<-Go to AI Workflows Go to ToC Conversation with Emotion->
| 1 Functions | 2 Reference Model | 3 I/O Data |
| 4 Functions of AI Modules | 5 I/O Data of AI Modules | 6 AIW, AIMx, and JSON Metadata |
| 7 Reference Software | 8 Conformance Texting | 9 Performance Assessment |
1 Functions of Conversation with Personal Status
When humans have a conversation with other humans, they use speech and, in constrained cases, text. Their interlocutors perceive speech and/or text supplemented by visual information related to the speaker’s face and gesture of a conversing human. Text, speech, face, and gesture may convey information about the internal state of the speaker that MPAI calls Personal Status. Therefore, handling of Personal Status information in a human-machine conversation and, in the future, even machine-machine conversation, is a key feature of a machine trying to understand what the speakers’ utterances mean because Personal Status recognition can improve understanding of the speaker’s utterance and help a machine produce better replies.
Conversation with Personal Status (MMC-CPS) is a general Use Case of an Entity – a real human or Digital Human – conversing with and asking questions to a machine. The machine captures and understands Text and Speech, extracts Personal Status from the Text, Speech, Face, and Gesture Factors, fuses the Factors’ Personal Statuses into an estimated Personal Status of the Entity to achieve a better understanding of the context in which the Entity utters Speech.
2 Reference Architecture of Conversation with Personal Status
Figure 1 gives the Conversation with Personal Status Reference Model including the input/output data, the AIMs, and the data exchanged between and among the AIMs.
The operation of the Conversation with Personal Status Use Case develops as follows:
- Input Selector is used to inform the machine whether the human employs Text or Speech in conversation with the machine.
- Visual Scene Description extracts the Scene Geometry, the Visual Objects and the Face and Body Descriptors of humans in the Scene.
- Audio Scene Description extracts the Scene Geometry, and the Speech Objects in the Scene.
- Visual Object Identification assigns an Identifier to each Visual Object indicated by a human.
- Audio-Visual Alignment uses the Audio Scene Description and Visual Scene Description to assign unique Identifiers to Audio, Visual, and Audio-Visual Objects.
- Automatic Speech Recognition recognises Speech utterances.
- Natural Language Understanding refines Text and extracts Meaning.
- Personal Status Extraction extracts a human’s Personal Status.
- Entity Dialogue Processing produces the machine’s response and its Personal Status.
- Personal Status Display produces a speaking Avatar expressing Personal Status.
- Audio-Visual Scene Rendering produces Machine Text, Speech, and Visual.
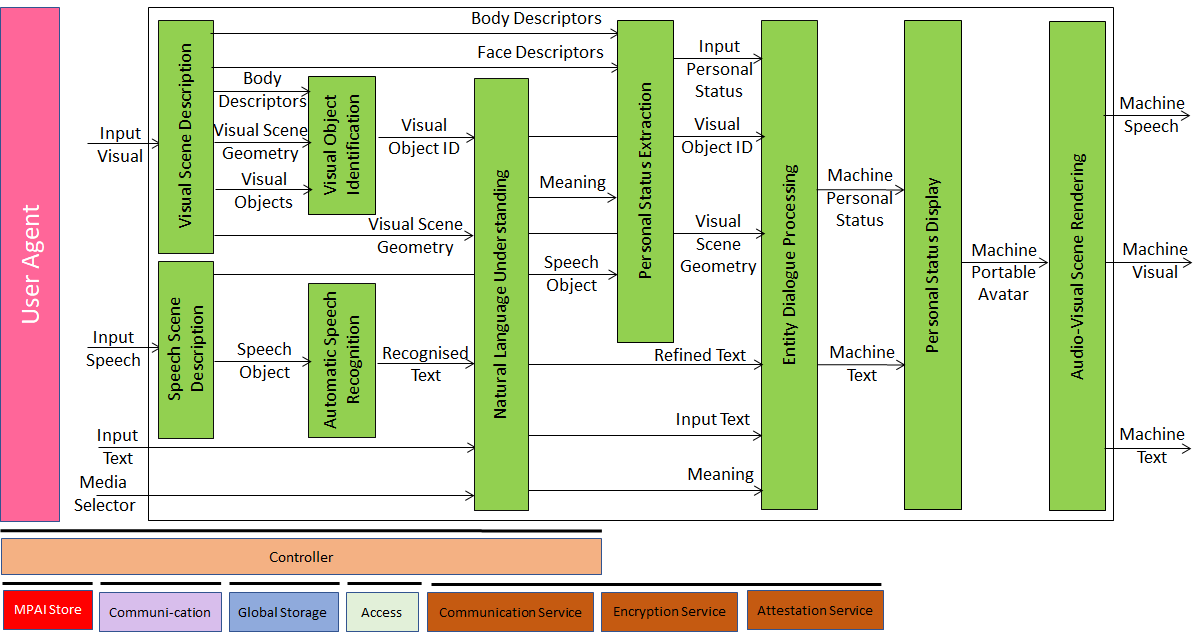
Figure 1 – Reference Model of Conversation with Personal Status
The operation of the Conversation with Personal Status Use Case develops as follows:
- Selector is used to inform the machine whether the human employs Text or Speech in conversation with the machine.
- Audio-Visual Scene Description extracts Audio Scene Geometry, Visual Scene Geometry, Audio Objects, Visual Objects, Face Descriptors and Body Descriptors of human in the Scene.
- Visual Object Identification assigns an Identifier to each Visual Object indicated by a human.
- Audio-Visual Alignment uses the Audio Scene Descriptors and Visual Scene Descriptors to assign unique Identifiers to Audio, Visual, and Audio-Visual Objects.
- Automatic Speech Recognition recognises Speech utterances.
- Natural Language Understanding refines Text and extracts Meaning.
- Personal Status Extraction extracts the human’s Personal Status.
- Entity Dialogue Processing produces the machine’s response as Text and Personal Status.
- Personal Status Display produces a speaking Portable Avatar expressing Personal Status.
- Audio-Visual Rendering produces Audio, Visual, and Text.
3 I/O Data of Conversation with Personal Status
Table 1 gives the input and output data of the Conversation with Personal Status Use Case:
Table 1 – I/O Data of Conversation with Personal Status
| Input | Descriptions |
| Input Text | Text typed by the human as additional information stream or as a replacement of the Speech. |
| Input Speech | Speech of the human having a conversation with the machine. |
| Input Visual | Visual information of the Face and Body of the human having a conversation with the machine. |
| Media Selector | Data determining the use of Speech vs Text. |
| Output | Descriptions |
| Output Text | Machine’s Text |
| Output Speech | Machine’s Audio (Speech) |
| Output Visual | Machine’s Visual |
4 Functions of AI Modules of Conversation with Personal Status
Table 2 provides the functions of the Conversation with Personal Status Use Case.
Table 2 – Functions of AI Modules of Conversation with Personal Status
| AIM | Function |
| Visual Scene Description | 1. Receives Input Visual. 2. Provides Visual Objects and Visual Scene Geometry. |
| Speech Scene Description | 1. Receives Input Speech. 2. Provides Speech Object. |
| Visual Object Identification | 1. Receives Visual Scene Geometry, Body Descriptors, and Visual Objects. 2. Provides Visual Object Instance IDs. |
| Automatic Speech Recognition | 1. Receives Speech Object. 2. Extracts Recognised Text. |
| Natural Language Understanding | 1. Receives Recognised Text, Visual Object ID, and Visual Scene Geometry 2. Refines Text and extracts Meaning. |
| Personal Status Extraction | 1. Receives Meaning, Refined Text, Body Descriptors, and Face Descriptors. 2. Extracts Personal Status. |
| Entity Dialogue Processing | 1. Receives Refined Text, Personal Status, Visual Object ID, and Visual Scene Geometry. 2. Produces Machine’s Text and Personal Status. |
| Personal Status Displays | 1. Receives Machine Text and Personal Status. 2. Multiplexes Machine Text and Personal Status into Machine Portable Avatar. |
| Audio-Visual Scene Rendering | 1. Receives Portable Avatar 2. Produces Machine Text, Machine Speech, and Machine Visual. |
5 I/O Data of AI Modules of Conversation with Personal Status
Table 3 provides the I/O Data of the AI Modules of the Conversation with Personal Status Use Case.
Table 3 – I/O Data of AI Modules of Conversation with Personal Status
| AIM | Receives | Produces |
| Visual Scene Description | 1. Input Visual | 1. Face Descriptors 2. Body Descriptors 3. Audio-Visual Scene Descriptors 4. Visual Objects |
| Speech Scene Description | 1. Input Speech | 1. Speech Object |
| Visual Object Identification | 1. Body Descriptors 2. Visual Scene Geometry 3. Visual Objects |
1. Visual Object ID |
| Automatic Speech Recognition | 1. Input Speech | 1. Recognised Text |
| Natural Language Understanding | 1. Visual Object ID 2. Input Speech 3. Recognised Text 4. Input Selector |
1. Meaning 2. Refined Text |
| Personal Status Extraction | 1. Face Descriptors 2. Body Descriptors 3. Meaning 4. Speech |
1. Input Personal Status |
| Entity Dialogue Processing | 1. Input Speech 2. Refined Speech 3. Input Personal Status 4. Input Selector |
1. Machine Personal Status 2. Machine Speech |
| Personal Status Displays | 1. Machine Speech 2. Machine Personal Status |
1. Machine Portable Avatar |
| Audio-Visual Scene Rendering | 1. Machine Portable Avatar | 1. Machine Text 2. Machine Speech 3. Machine Visual |
6 JSON Metadata of Conversation with Personal Status
Table 4 provides the links to the AIW and AIM specifications and to the JSON syntaxes. AIMs/1 indicates that the column contains Composite AIMs and AIMs/2 indicates that the column contains their Basic AIMs.
Table 4 – Acronyms and URLs of JSON Metadata