<-Go to AI Workflows Go to ToC Multimodal Question Answering->
| 1 Functions | 2 Reference Model | 3 I/O Data |
| 4 Functions of AI Modules | 5 I/O Data of AI Module | 6 AIW, AIMs, AIMs and JSON Metadata |
| 7 Reference Software | 8 Conformance Texting | 9 Performance Assessment |
1 Functions of Human-CAV Interaction Subsystem
The Human-CAV interaction (HCI) Subsystem has the function to recognise the human owner or renter, respond to humans’ commands and queries, converse with humans during the travel, exchange information with the Autonomous Motion Subsystem in response to humans’ requests, and communicate with HCIs on board other CAVs.
2 Reference Model of Human-CAV Interaction Subsystem
Figure 1 represents the Human-CAV Interaction (HCI) Reference Model.
Note that it is assumed that Natural Language Understanding produces a Refined Text that is either the refined Recognised Text or the Input Text, depending on which one is active. Meaning is always computed based on the available text – Refined or Input. Personal Status Extraction is unaware of the decisions made by Natural Language Understanding.
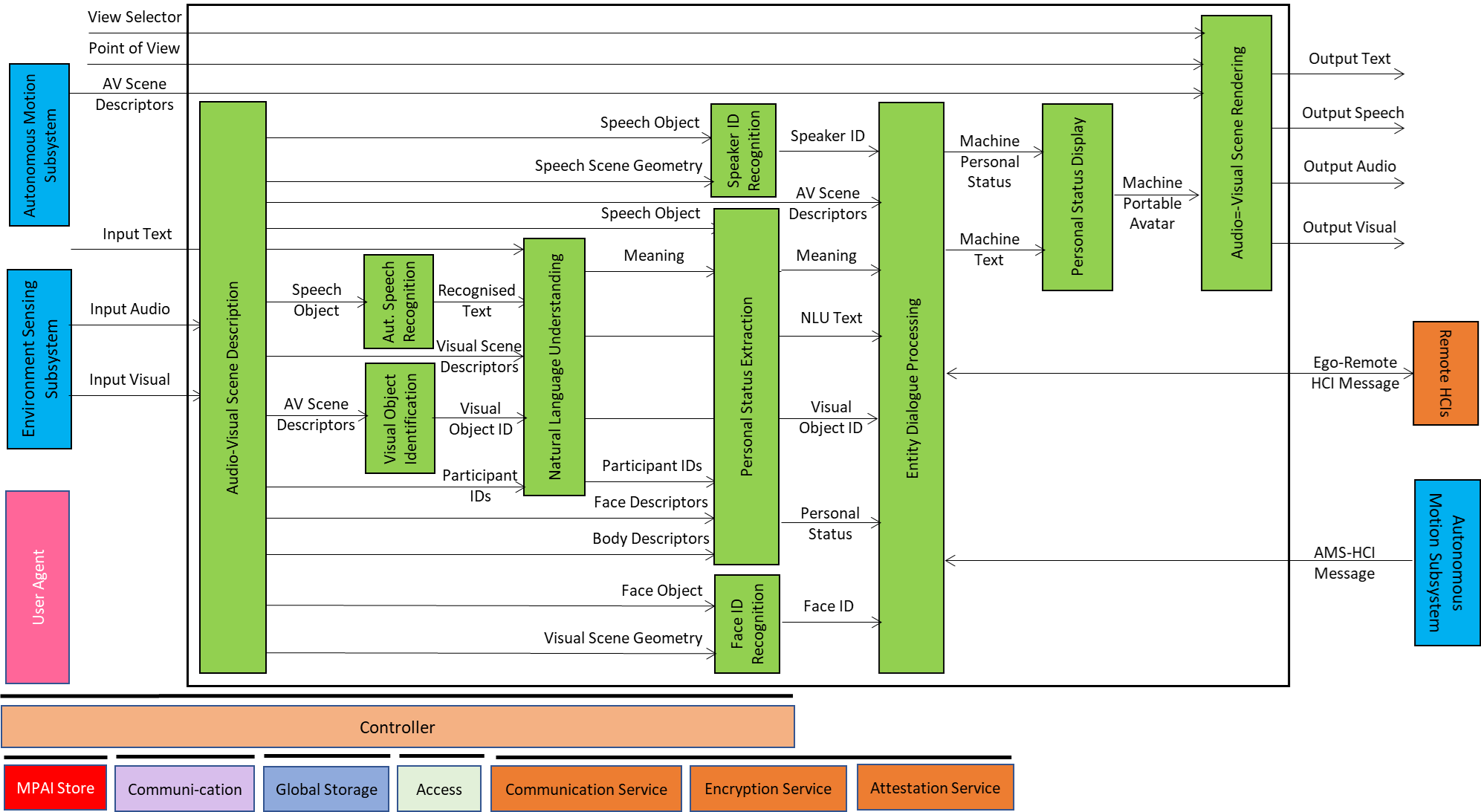
Figure 1 – Human-CAV Interaction Reference Model
A group of humans approaches the CAV outside the CAV or is sitting inside the CAV:
- Audio-Visual Scene Description produces:
- Speech Scene Descriptors in the form of Speech Objects corresponding to each speaking human in the Environment (outside or inside the CAV)..
- Visual Scene Descriptors in the form of Descriptors of Faces and Bodies.
- All non-Speech Objects are removed from or signalled in the Audio Scene.
- Automatic Speech Recognition recognises the speech of each human and produces Recognised Text supporting multiple Speech Objects as input properly identified by the Spatial Attitude.
- Visual Object Identification produces Instance IDs of Visual Objects indicated by humans.
- Natural Language Understanding produces Refined Text and extracts Meaning from the Recognised Text of each Input Speech using the spatial information of Visual Object Identifiers.
- Speaker Identity Recognition and Face Identity Recognition identifies the humans the HCI is interacting with. If the Face Identity Recognition AIM provides Face IDs corresponding to the Speaker IDs, the Entity Dialogue Processing AIM can correctly associate the Speaker IDs (and the corresponding Text) with the Face IDs.
- Personal Status Extraction extracts the Personal Status of the humans.
- Entity Dialogue Processing
- Communicates with the Autonomous Motion Subsystem of the Ego CAV to request to:
- Move the CAV to a destination.
- Views the Full Environment Descriptors for the passengers’ benefit.
- Be informed about CAV’s situation.
- Receive relevant information for passengers.
- Communicates with the Autonomous Motion Subsystems of Remote CAVs.
- Produces the Machine Speech and Machine Personal Status.
- Communicates with the Autonomous Motion Subsystem of the Ego CAV to request to:
- Personal Status Display produces the Machine Portable Avatar conveying Machine Speech, Machine Personal Status, and any other information that may be relevant to the conversation.
- Audio-Visual Scene Rendering renders Audio-Visual information using Machine Portable Avatar or the Autonomous Motion Subsystem’s Full Environment Descriptors based on the Point of View provided by the human.
The HCI interacts with the humans in the cabin in several ways:
- By responding to commands/queries from one or more humans at the same time, e.g.:
- Commands to go to a waypoint, park at a place, etc.
- Commands with an effect in the cabin, e.g., turn off air conditioning, turn on the radio, call a person, open window or door, search for information etc.
- By conversing with and responding to questions from one or more humans at the same time about travel-related issues (in-depth domain-specific conversation), e.g.:
- Humans request information, e.g., time to destination, route conditions, weather at destination, etc.
- CAV offers alternatives to humans, e.g., long but safe way, short but likely to have interruptions.
- Humans ask questions about objects in the cabin.
- By following the conversation on travel matters held by humans in the cabin if 1) the passengers allow the HCI to do so, and 2) the processing is carried out inside the CAV.
The HCI interacts with the Ego-AMS and with Remote HCIs exchanging context-based messages.
3 I/O Data of Human-CAV Interaction
Table 1 gives the input/output data of Human-CAV Interaction. I/O Data to/from Remote HCI and Ego AMS are not part of this Technical Specification.
Table 1 – I/O data of Human-CAV Interaction
| Input data | From | Comment |
| Input Audio | Environment, Passenger Cabin | User authentication, command/interaction with HCI, etc. |
| Input Text | User | Text complementing/replacing User input |
| Input Visual | Environment, Passenger Cabin | Environment perception, User authentication, command/interaction with HCI, etc. |
| AMS-HCI Message | AMS Subsystem | AMS response to HCI request. |
| Ego-Remote HCI Message | Remote HCI | Remote HCI to Ego HCI. |
| Output data | To | Comment |
| Output Text | Cabin Passengers | HCI’s avatar Text. |
| Output Speech | Cabin Passengers | HCT’s avatar Speech. |
| Output Audio | Cabin Passengers | HCI’s avatar or FED Audio. |
| Output Visual | Cabin Passengers | HCI’s avatar or FED Visual. |
| AMS-HCI Message | AMS Subsystem | HCI request to AMS, e.g., Route or Point of View. |
| Ego-Remote HCI Message | Remote HCI | Ego HCI to Remote HCI. |
4 Functions of AI Modules of Human-CAV Interaction
Table 2 gives the functions of all Human-CAV Interaction AIMs.
Table 2 – Functions of Human-CAV Interaction’s AI Modules
| AIM | Function |
| Audio-Visual Scene Description | 1. Receives Audio and Visual Objects from the appropriate Devices. 2. Produces Audio-Visual Scene Descriptors. |
| Automatic Speech Recognition | 1. Receives Speech Objects. 2. Produces Recognised Text. |
| Visual Object Identification | 1. Receives Visual Scenes Descriptors. 2. Provides Instance ID of indicated Visual Object. |
| Natural Language Understanding | 1. Receives Recognised Text. 2. Uses context information (e.g., Instance ID of object). 3. Produces Natural Language Understanding Text (using Refined or Input) and Meaning. |
| Speaker Identity Recognition | 1. Receives Speech Object of a human and Speech Scene Geometry. 2. Produces Speaker ID. |
| Personal Status Extraction | 1. Receives Speech Object, Meaning, Face Descriptors and Body Descriptors of a human with a Participant ID. 2. Produces the human’s Personal Status. |
| Face Identity Recognition | 1. Receives Face Object of a human and Visual Scene Geometry. 2. Produces Face ID. |
| Entity Dialogue Processing | 1. Receives Speaker ID, Face ID, AV Scene Descriptors, Meaning, Natural Language Understanding Text , Visual Object ID, and Personal Status. Moreover it receives AMS-HCI Messages and Ego-Remote HCI Messages. 2. Produces Machine (HCI) Text Object and Personal Status. Moreover it produces AMS-HCI Messages and Ego-Remote HCI Messages. |
| Personal Status Display | 1. Receives Machine Text Object and Machine Personal Status. 2. Produces Machine’s Portable Avatar. |
| Audio-Visual Scene Rendering | 1. Receives AV Scene Descriptors, Portable Avatar, and View Selector. 2. Produces Output Text, Output Speech, Output Audio, and Output Visual. |
5 I/O Data of AI Modules of Human-CAV Interaction
Table 3 gives the AI Modules of the Human-CAV Interaction depicted in Figure 3.
Table 3 – AI Modules of Human-CAV Interaction AIW
6 AIW, AIMs and JSON Metadata
Table 4 provides the links to the AIW and AIM specifications and to the JSON syntaxes. AIMs/1 indicates that the column contains Composite AIMs and AIMs/2 indicates that the column contains Basic and Composite AIMs. AIMs/3 indicates the the column only contains Basic AIMs.
Table 4 – AIMs and JSON Metadata
7 Reference Software
8 Conformance Testing
9 Performance Assessment
<-Go to AI Workflows Go to ToC Multimodal Question Answering->