Go to MPAI-MMC V2.5 AI Modules
Function
Ref. Model
I/O Data
SubAIMs
JSON MData
Profiles
Ref. Software
Conformance
Performance
1 Functions
The Automatic Speech Recognition (MMC-ASR) AIM extracts the text conveyed by an utterance and derives the paralinguistic features of the speech signal. The input speech may be accompanied by an auxiliary text, the identifier of the speaker, the Speech Overlap data type, and the time indicating the portion of the input speech that should be recognised.
In V2.5, MMC-ASR extends its output with Speech Descriptors, providing downstream AIMs with paralinguistic information — including prosody, vocal affect, and speaker characteristics — derived from the same speech signal used for recognition. This information has general value across MPAI applications and requires no additional input beyond what is already provided to the AIM.
| Receives | Language Selector | Signalling the language of the speech. |
| Auxiliary Text | Text that may be used to provide context information. | |
| Speech Object | Speech to be recognised. | |
| Speaker ID | ID of speaker uttering speech. | |
| Speech Overlap | Data type providing information on speech overlap. | |
| Speaker Time | Time during which the speech is to be recognised. | |
| Produces | Recognised Text | Text transcript of the recognised speech. |
| Speech Descriptors | Paralinguistic features of the recognised speech segment. |
2 Reference Model
Figure 1 depicts the Reference Model of the Automatic Speech Recognition (MMC-ASR) AIM.
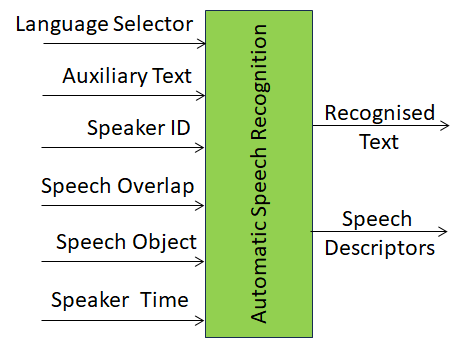
Figure 1 – The Automatic Speech Recognition (MMC-ASR) AIM
3 I/O Data
Table 1 specifies the Input and Output Data of the Automatic Speech Recognition (MMC-ASR) AIM.
| Input | Description |
|---|---|
| Language Selector | Selects input language. |
| Auxiliary Text Object | Text Object with content related to Speech Object. |
| Speech Object | Speech Object emitted by Entity. |
| Speaker Identifier | Identity of Speaker. |
| Speech Overlap | Times and IDs of overlapping speech segments. |
| Speaker Time | Time during which Speech is recognised. |
| Output | Description |
| Recognised Text Object | Output of the Automatic Speech Recognition AIM — a Text Segment or just a string. |
| Speech Descriptors | Paralinguistic features of the speech segment including prosody, vocal affect, speaker characteristics, and optional neural network descriptors. |
4 SubAIMs
No SubAIMs.
5 JSON Metadata
https://schemas.mpai.community/MMC/V2.5/AIMs/AutomaticSpeechRecognition.json
6 Profiles
No Profiles.
7 Reference Software
7.1 Disclaimers
- This MMC-ASR Reference Software Implementation is released with the BSD-3-Clause licence.
- The purpose of this Reference Software is to demonstrate a working Implementation of MMC-ASR, not to provide a ready-to-use product.
- MPAI disclaims the suitability of the Software for any other purposes and does not guarantee that it is secure.
- Use of this Reference Software may require acceptance of licences from the respective repositories. Users shall verify that they have the right to use any third-party software required by this Reference Software.
7.2 Guide to the ASR code #1
The code takes Speech Objects from MMC-AUS and generates Text Segments (called text transcripts). It uses the whisper-large-v3 model to convert an input Speech Object (speaker’s turn) into a Text Segment (here called text transcript). Disfluencies (e.g., repetitions, repairs, filled pauses) are often omitted. The Whisper reference document is available.
The MMC-ASR Reference Software is found at the MPAI gitlab site. Use of this AI Module is for developers who are familiar with Python, Docker, RabbitMQ, and downloading models from HuggingFace. The Reference Software contains:
- src: a folder with the Python code implementing the AIM.
- Dockerfile: a Docker file containing only the libraries required to build the Docker image and run the container.
- requirements.txt: dependencies installed in the Docker image.
- README.md: commands for cloning https://huggingface.co/openai/whisper-large-v3.
Library: https://github.com/linto-ai/whisper-timestamped
7.3 Guide to the ASR code #2
Use of this AI Module is for developers who are familiar with Python and downloading models from HuggingFace.
A wrapper for the Whisper NN Module:
- Manages input files and parameters: Speech Object.
- Performs Speech Recognition on each Speech Object by executing the Whisper Module.
- Outputs Recognised Text.
The MMC-ASR Reference Software is found at the NNW gitlab site (registration required). It contains:
- The Python code implementing the AIM.
- The required libraries are: pytorch and transformers (HuggingFace).
7.4 Acknowledgements
This version of the MMC-ASR Reference Software
- #1 has been developed by the MPAI AI Framework Development Committee (AIF-DC).
- #2 has been developed by the MPAI Neural Network Watermarking Development Committee (NNW-DC).
8 Conformance Testing
Table 2 provides the Conformance Testing Method for the MMC-ASR AIM.
If a schema contains references to other schemas, conformance of data for the primary schema implies that any data referencing a secondary schema shall also validate against the relevant schema, if present, and conform with the Qualifier, if present.
Table 2 – Conformance Testing Method for the MMC-ASR AIM
| Input | Language Selector | Shall validate against the Language Selector part of the schema. |
| Auxiliary Text | Shall validate against the Text Object schema. Text Data shall conform with the Text Qualifier. | |
| Speech Object | Shall validate against the Speech Object schema. Speech Data shall conform with the Speech Qualifier. | |
| Speaker ID | Shall validate against the Instance ID schema. | |
| Speech Overlap | Shall validate against the Speech Overlap schema. | |
| Speaker Time | Shall validate against the Time schema. | |
| Output | Text Object | Shall validate against the Text Object schema. Text Data shall conform with the Text Qualifier, e.g. output language shall be that indicated by the Language Selector. |
| Speech Descriptors | Shall validate against the Speech Descriptors schema. |
Table 3 provides an example of MMC-ASR AIM Conformance Testing.
| Input Data | Data Format | Input Conformance Testing Data |
|---|---|---|
| Speech Object | .wav | All input Speech files to be drawn from Speech files. |
| Output Data | Data Format | Output Conformance Testing Criteria |
| Recognised Text | Unicode | All Text files produced shall conform with Text files. |
9 Performance Assessment
Performance Assessment of an ASR Implementation (ASRI) can be performed for a language for which there is a dataset of speech segments of various durations with corresponding Transcription Text. An MMC-ASR AIM Performance Assessment Report shall be based on the following steps and specify the input dataset used.
For each Recognised Text produced by the ASRI being Assessed for Performance in response to a speech segment provided as input:
- Compare the Recognised Text with the Transcription Text.
- Compute the Word Error Rate (WER) defined as the sum of deletion, insertion, and substitution errors in the Recognised Text compared to the Transcription Text, divided by the total number of words in the Transcription Text.
This code can be used to compute the WER.
Performance Assessment of an ASRI for a language in a Performance Assessment Report is defined as “The WER computed on all speech segments included in the reported dataset”.