Go to MPAI-MMC V2.5 AI Modules
Function
Ref. Model
I/O Data
SubAIMs
JSON MData
Profiles
Ref. Software
Conformance
Performance
1 Functions
The Answer to Multimodal Question (MMC‑AMQ) AIM receives a question expressed as a Text Object or a Speech Object and an Image and provides Text and/or Speech giving information in response to the question.
2 Reference Model
Figure 1 depicts the Reference Model of the Answer to Multimodal Question (MMC‑AMQ) AIM.
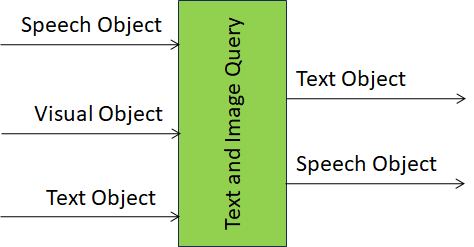
Figure 1 – Reference Model of the Answer to Multimodal Question (MMC‑AMQ) AIM
The operation of the Answer to Multimodal Question (MMC‑AMQ) AIM develops in the following way:
- A user provides:
- Text Object or Speech Object.
- An Image.
- The machine provides the answer expressed as Text Object and/or Speech Object.
3 I/O Data
Table 1 specifies the Input and Output Data of the Answer to Multimodal Question (MMC‑AMQ) AIM.
| Input | Description |
|---|---|
| Text Object | Text typed by the human as a replacement for Input Speech. |
| Image Visual Object | Image about which a question is asked. |
| Speech Object | Speech question to the machine. |
| Output | Description |
| Machine Text | The Text generated by the machine in response to human input. |
| Machine Speech | The Speech generated by the machine in response to human input. |
4 SubAIMs
4.1 Reference Model
Figure 2 depicts the Reference Model of the Answer to Multimodal Question (MMC‑AMQ) Composite AIM.
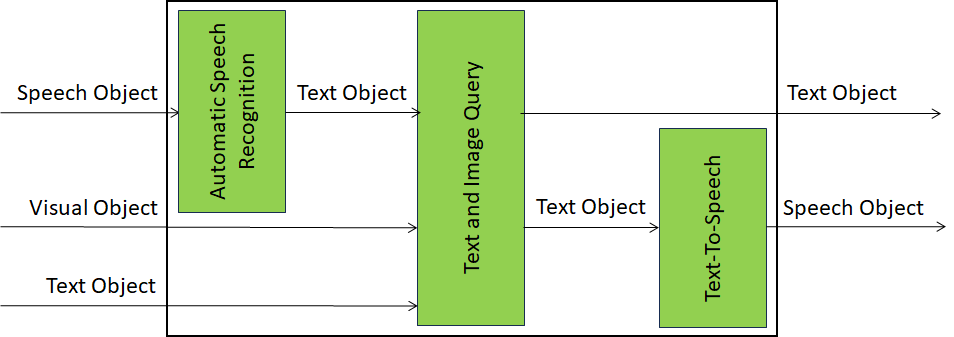
Figure 2 – Reference Model of the Answer to Multimodal Question (MMC‑AMQ) Composite AIM
4.2 Operation
The Answer to Multimodal Question (MMC‑AMQ) AIM receives an optional Speech Object that Automatic Speech Recognition converts to Text. The Text and Image Visual Object are then processed by Text and Image Query to produce Machine Text. Text-to-Speech synthesises Machine Speech from Machine Text.
4.3 Functions of SubAIMs
Table 2 provides the functions of the Answer to Multimodal Question (MMC‑AMQ) SubAIMs.
| SubAIM | Function |
|---|---|
| Automatic Speech Recognition | Recognises as Text an input Speech. |
| Text and Image Query | Receives an input text and an input image and produces an output text that is a response to the inputs. |
| Text-to-Speech | Receives an input text and produces a synthetic speech version of it. |
4.4 I/O Data of SubAIMs
Table 3 gives the Input and Output Data of the Answer to Multimodal Question (MMC‑AMQ) SubAIMs.
| SubAIM | Input | Output |
|---|---|---|
| Automatic Speech Recognition | Speech Object | Recognised Text |
| Text and Image Query | Text Object Image Visual Object |
Machine Text |
| Text-to-Speech | Machine Text | Machine Speech |
4.5 AIMs and JSON Metadata
Table 4 provides the links to the AIM specifications and JSON schemas. AIM1 indicates the Composite AIM and AIM2 its SubAIMs.
| AIM1 | AIM2 | Name | JSON |
|---|---|---|---|
| MMC‑AMQ | Answer to Multimodal Question | X | |
| MMC‑ASR | Automatic Speech Recognition | X | |
| MMC‑TIQ | Text and Image Query | X | |
| MMC‑TTS | Text-to-Speech | X |
5 JSON Metadata
https://schemas.mpai.community/MMC/V2.5/AIMs/AnswerToMultimodalQuestion.json
6 Profiles
No Profiles.
7 Reference Software
7.1 Disclaimers
- This MMC‑AMQ Reference Software Implementation is released with the BSD-3-Clause licence.
- The purpose of this Reference Software is to demonstrate a working Implementation of MMC‑AMQ, not to provide a ready-to-use product.
- MPAI disclaims the suitability of the Software for any other purposes and does not guarantee that it is secure.
- Use of this Reference Software may require acceptance of licences from the respective repositories. Users shall verify that they have the right to use any third-party software required by this Reference Software.
7.2 Guide to the MMC‑AMQ code
Use of this AI Module is for developers who are familiar with Python and downloading models from HuggingFace.
A wrapper for three models is provided: Whisper (ASR), BLIP (TIQ), and SpeechT5 (TTS):
- Manages input files and parameters: Speech Object, Visual Object, Text Object.
- Executes the AIM performing the Answer to Multimodal Question on each individual pair of Speech/Text and Visual Object.
- Outputs the answer as Speech Object and Text Object.
The MMC‑AMQ Reference Software is found at the MPAI gitlab site. It contains:
- The Python code implementing the AIM.
- The required libraries are: pytorch, transformers (HuggingFace), datasets (HuggingFace), soundfile, and pillow.
7.3 Acknowledgements
This version of the MMC‑AMQ Reference Software has been developed by the MPAI Neural Network Watermarking Development Committee (NNW‑DC).
8 Conformance Testing
Table 5 provides the Conformance Testing Method for the Answer to Multimodal Question (MMC‑AMQ) AIM. Conformance Testing of the individual SubAIMs is given by the individual AIM specifications.
If a schema contains references to other schemas, conformance of data for the primary schema implies that any data referencing a secondary schema shall also validate against the relevant schema, if present, and conform with the Qualifier, if present.
| Receives | Text Object | Shall validate against Text Object schema. Text Data shall conform with Text Qualifier. |
| Image Visual Object | Shall validate against Visual Object schema. Visual Data shall conform with Visual Qualifier. | |
| Speech Object | Shall validate against Speech Object schema. Speech Data shall conform with Speech Qualifier. | |
| Produces | Machine Text | Shall validate against Text Object schema. Text Data shall conform with Text Qualifier. |
| Machine Speech | Shall validate against Speech Object schema. Speech Data shall conform with Speech Qualifier. |
9 Performance Assessment
Not part of this specification.