| Function | Ref. Model | I/O Data | SubAIMs | JSON MData | Profiles | Ref. Software | Conformance | Performance |
1. Function
The Visual Scene Enhancement (PGM‑VSE) AIM takes a best‑effort Visual Scene Descriptors instance produced by the Visual Scene Description (PGM‑VSD) AIM and refines it using contextual directives, domain knowledge, and interaction history.
Visual Scene Enhancement:
- Operates on the Visual Object, the Visual CXT Directive received from A‑User Control, the Visual Domain Response resulting from queries made to Domain Access, and the Visual IH Response resulting from queries made to Interaction History.
- Identifies and classifies Visual Objects in the scene using contextual and domain directives.
- Infers Affordance Tags and Interaction Potential for identified objects.
- Produces a Salient Object Matrix ranking objects by perceptual importance and interaction relevance.
- Produces the Enhanced Visual Scene Descriptors sent to Audio‑Visual Alignment and Context Description Multiplexing, the Visual CXT Status, the Visual Domain Request when querying Domain Access, and the Visual IH Request when querying Interaction History.
The Enhanced Visual Scene Descriptors carry the perceptual semantics of the scene augmented with identified objects, affordances, and salience rankings, under Visual CXT Directive control.
2. Reference Model
Figure 1 depicts the Reference Model of the Visual Scene Enhancement (PGM‑VSE) AIM.
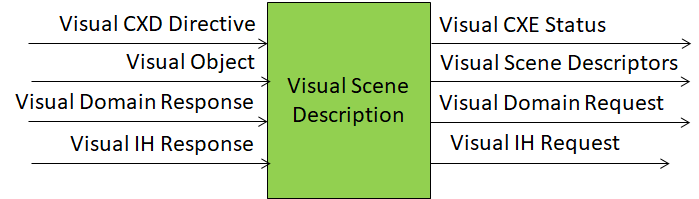
Figure 1 – Reference Model of the Visual Scene Enhancement (PGM‑VSE) AIM
3. Input/Output Data
Table 1 lists the Input and Output Data of the Visual Scene Enhancement (PGM‑VSE) AIM.
Table 1 – Input/Output Data of the Visual Scene Enhancement (PGM‑VSE) AIM
| Input | Description |
| Visual Object | Best‑effort Visual Scene Descriptors produced by the VSD AIM. |
| Visual CXT Directive | Contextual directive specifying scope, depth, and policy constraints for visual enhancement. |
| Visual Domain Response | Domain‑specific knowledge supporting visual object classification and semantic interpretation. |
| Visual IH Response | Interaction History response providing temporal context for scene understanding. |
| Output | Description |
| Enhanced Visual Scene Descriptors | Refined Visual Scene Descriptors integrating identified objects, affordances, and salience rankings. |
| Visual CXT Status | Multiplexed status signals from Visual Object Identification, Affordance Inference, and Visual Salience Mapping reporting their processing outcomes. |
| Visual Domain Request | Multiplexed domain requests from Visual Object Identification, Affordance Inference, and Visual Salience Mapping. |
| Visual IH Request | Multiplexed Interaction History requests from Visual Object Identification, Affordance Inference, and Visual Salience Mapping. |
4. SubAIMs (Informative)
This section is informative. The decomposition into SubAIMs described below illustrates one conformant architecture for producing the normative outputs of PGM‑VSE. Implementations may adopt alternative internal structures provided they satisfy the conformance requirements of Section 8.
4.1 Reference Model
Figure 2 depicts the Reference Model of the Visual Scene Enhancement (PGM‑VSE) Composite AIM.
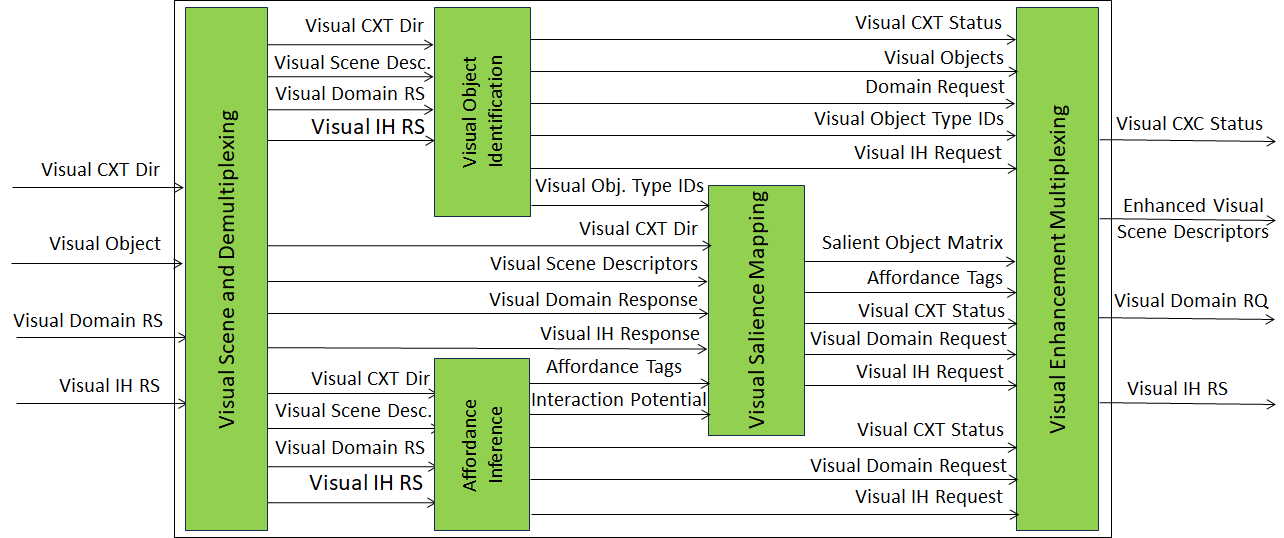
Figure 2 – Reference Model of the Visual Scene Enhancement (PGM‑VSE) Composite AIM
4.2 Operation
The Visual Scene Enhancement operation receives a best‑effort Visual Scene Descriptors instance and progressively enriches it through a sequence of specialised SubAIMs. The Visual Scene and Demultiplexing SubAIM constructs the initial scene representation and routes the control signals to the appropriate SubAIMs. Visual Object Identification assigns semantic labels to detected objects using domain knowledge. Affordance Inference determines the possible interactions with objects and their feasibility. Visual Salience Mapping ranks objects by perceptual importance and interaction relevance and produces the Salient Object Matrix. The Visual Enhancement Multiplexing SubAIM collects the outputs of all SubAIMs and assembles the Enhanced Visual Scene Descriptors together with the multiplexed status and request signals.
Each of Visual Object Identification, Affordance Inference, and Visual Salience Mapping independently generates a Visual CXT Status, a Visual Domain Request, and a Visual IH Request, which are multiplexed by Visual Enhancement Multiplexing into the corresponding external output signals.
4.3 Functions of SubAIMs
Table 2 specifies the functions of the SubAIMs of the Visual Scene Enhancement (PGM‑VSE) Composite AIM.
Table 2 – Functions of the SubAIMs of the Visual Scene Enhancement (PGM‑VSE) Composite AIM
| Name | Function |
| Visual Scene and Demultiplexing | Receives the external inputs, constructs the initial Visual Scene Descriptors from the best‑effort VSD input, and routes the control signals to the appropriate SubAIMs. |
| Visual Object Identification | Assigns semantic object‑type labels to visual objects using classification models and optional domain knowledge. |
| Affordance Inference | Infers Affordance Tags and Interaction Potential describing the possible interactions with objects and their feasibility, combining object properties, spatial constraints, and domain information. |
| Visual Salience Mapping | Determines the relative perceptual importance of visual objects with respect to user interaction and context, and produces the Salient Object Matrix. |
| Visual Enhancement Multiplexing | Collects outputs from all SubAIMs and assembles the Enhanced Visual Scene Descriptors and the multiplexed Visual CXT Status, Visual Domain Request, and Visual IH Request. |
4.4 Input/Output Data of SubAIMs
Table 3 lists the Input and Output Data of the SubAIMs of the Visual Scene Enhancement (PGM‑VSE) Composite AIM.
Table 3 – Input/Output Data of the SubAIMs of the Visual Scene Enhancement (PGM‑VSE) Composite AIM
4.5 AIMs and JSON Metadata
Table 4 gives the Visual Scene Enhancement (AIM1) and its SubAIMs (AIM2).
Table 4 – Visual Scene Enhancement (AIM1) and its SubAIMs (AIM2)
| AIM1 | AIM2 | Name | JSON |
| PGM‑VSE | Visual Scene Enhancement | X | |
| PGM‑VSX | Visual Scene and Demultiplexing | X | |
| PGM‑VOI | Visual Object Identification | X | |
| PGM‑AFI | Affordance Inference | X | |
| PGM‑VSM | Visual Salience Mapping | X | |
| PGM‑VEM | Visual Enhancement Multiplexing | X |
5. JSON Metadata
https://schemas.mpai.community/PGM1/V1.0/AIMs/VisualSceneEnhancement.json
6. Profiles
No Profiles.
7. Reference Software
Not part of this specification.
8. Conformance Testing
A VSE implementation conforms with Visual Scene Enhancement (PGM‑VSE) if:
- The implementation includes all SubAIMs listed in Table 2.
- All I/O Data listed in Table 1 are present and conform with their respective Data Types.
- All SubAIM I/O Data listed in Table 3 conform with their respective Data Types.
- The implementation produces Enhanced Visual Scene Descriptors that refine the input Visual Scene Descriptors using the outputs of Visual Object Identification, Affordance Inference, and Visual Salience Mapping.
9. Performance Assessment
Not part of this specification.