| 1. Functions | 2. Reference Model | 3. Input/Output Data |
| 4. Functions of AI Modules | 5. Input/output Data of AI Modules | 6. AIW, AIMs, and JSON Metadata |
1. Functions
Data from both the Real and Virtual Environments (called Data In) of a Live Theatrical Performance specified by XRV-LTP (see Figure) include audio, video, volumetric or motion capture (mocap), and avatar data from performers, participants, operators, signals from control surfaces and more as defined by the Real Venue (RE)/Virtual Venue (VE) Specifications that describe the technology choices and configurations (e.g., data format as specified by MPAI-TFA) made by a particular Venue.
This Input Data is processed and converted into RE (Real Environment, i.e., the theatre) and VE (Virtual Environment, i.e., the metaverse) Performance, Participant, and Operator Descriptors that are fed into the Performance and Participant Status Interpretation and the Operator Command Interpretation AIMs.
The show execution is guided by a Script, which includes a Cue List. Each Cue has multiple groups each with an associated set of Cue Conditions, Actions to be executed and the next Cue to branch to when those Conditions are met.
When a performance starts the Cues are executed in sequential order. The current Cue is referred to as the Cue Point. When the current Cue Conditions within a given group are satisfied, its associated Actions are executed, and the Cue Point branches to the next Cue. For each Cue ID there can exist multiple groups of Cue Conditions, their associated Actions, and the next Cue. The Action Generation AIM sends the new Cue Point ID to the three Interpretation AIMs.
When the specific Cue Point Conditions (RE or VE) have been met, the Action Generation AIM outputs the set of RE and VE Action IDs associated with that Cue. The set of Action IDs for a specific Cue Point references the Action List which includes, for each Action ID, an associated natural language semantic as it appears in the Script and a set of associated Action Commands.
The Action List is built during Show Programming Phase by an automatic or manual process wherein each real or virtual object is commanded to achieve a desired Action in the Venue per the Script. The Action Commands associated with the desired Action per the Script are entered into the Action List and assigned an Action ID and associated mnemonic. The Real or Virtual Venue Specifications include 3D Model Scenes that are Annotated with the full Venue-specific Command set for each object to be commanded.
The RE and VE Experience Generation AIMs produce RE and VE Data Out that include Action Commands from the Action List and Data from the Show Descriptors required by the Real and Virtual Environments – according to the respective Venue Specifications – to provide multisensory experiences in both Venues.
2. Reference Model
Figure 1 depicts the Reference Architecture of Live Theatrical Stage Performance.
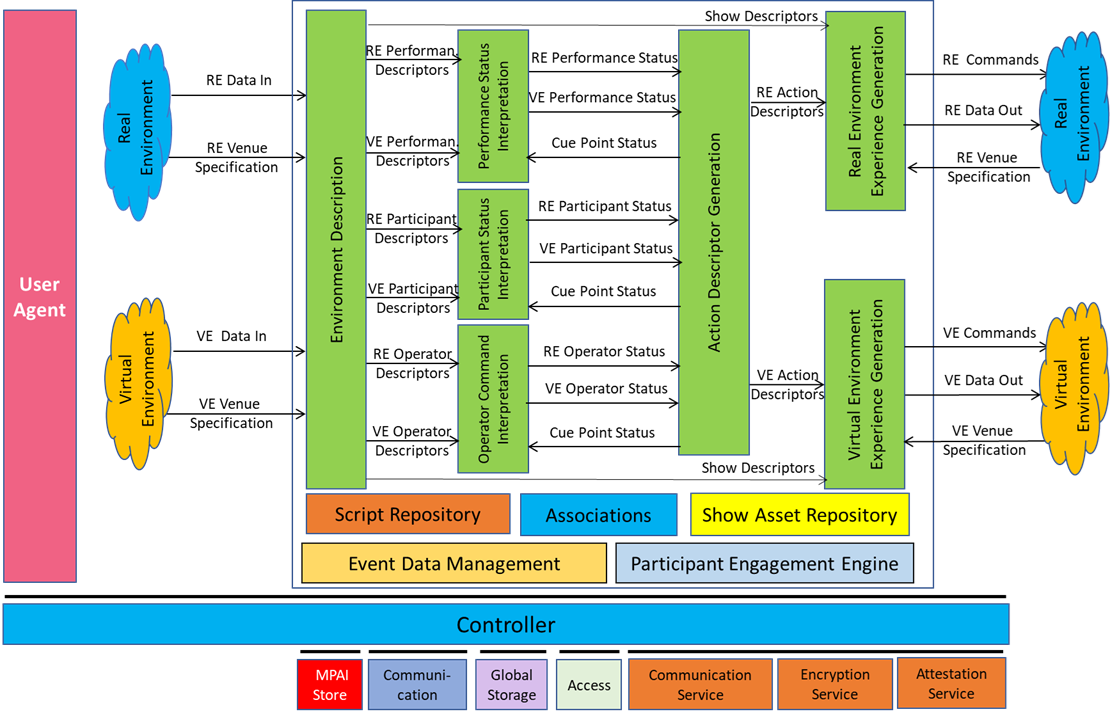
Figure 1 – Reference Model of Live Theatrical Stage Performance (XRV-LTP) AIW
This is the flow of operation of the XRV-LTP AIW Reference Model:
- A range of sensors/controllers collect Data from both the Real and Virtual Environments including audio, video, volumetric or motion capture (mocap) and avatar data from performers, signals from control surfaces and more.
- The Environment Description AIM
- Extracts features from performers and objects, participants, and operators,
- Conditions the data and provides them as
- Performance Descriptors (including description of behaviour of performers and objects on the stage or in the metaverse),
- Participant Descriptors (describing the audience’s behaviour)
- Operator Descriptors (Data from the Show Control computer or control surface, consoles for audio, DJ, VJ, lighting and FX, typically commanded by operators)
- Show Data (which includes real-time data streams such as MoCap and Volumentric which are used for RE and VE Experience Generation).
- The Performance, Participant, and Operator Status Interpretation AIMs determine the components of the Performance, Participant, and Operator Descriptors that are relevant to the current Cue Point provided by the Action Generation AIM.
- Action Descriptors Generation uses Performance Status, Participant Status, and Operator Status to direct actions in both the Real and Virtual Environments via RE and VE Action Descriptors, and provides the current Cue Point to the three Interpretation AIMs.
- VE Experience Generation and RE Experience Generation uses Show Data from Environment Descriptors and converts RE and VE Action Descriptors into actionable commands required by the Real and Virtual Environments – according to their Venue Specifications – to enable multisensory experience generation in both the Real and Virtual Environments.
3. Input/Output Data
Table 2 specifies the Input and Output Data.
Table 2 – I/O Data of MPAI-XRV – Live Theatrical Stage Performance
| Input | Description |
| RE Data In | Input data such as App Data, Audio/VJ/DJ, Audio-Visual, Biometric Data, Controller, Lidar, Lighting/FX, MoCap, Sensor Data, Show Control, Skeleton/Mesh, and Volumetric data. |
| RE Venue Specification | An input to the Environment Description AIM and the Real Experience Generation AIM defining protocols, data formats, and command structures for the specific Real Environment Venue and also includes number, type, and placement of lighting fixtures, special effects, sound and video reproduction resources. |
| VE Data In | App Data, Audio/VJ/DJ, Audio-Visual, Biometric Data, Controller, Lidar, Lighting/FX, MoCap, Sensor Data, Show Control, Skeleton/Mesh, and Volumetric data. |
| VE Venue Specification | An input to the Virtual Experience Generation AIM defining protocols, data formats, and command structures for the specific Virtual Environment Venue and also includes all actionable elements relevant to the Script including number, type, and placement of lights, effects, avatars, objects, animation scripts, and sound and video reproduction resources. |
| Output | Description |
| VE Data Out | Parameters controlling 3D geometry, shading, lighting, materials, cameras, physics, and all A/V experiential elements, including audio, video, and capture cameras/microphones. The actual format used is specified by the Virtual Environment Venue Specification. |
| VE Commands | Commands controlling 3D geometry, shading, lighting, materials, cameras, physics, and all A/V experiential elements, including audio, video, and capture cameras/microphones. Relevant commands are specified by the Virtual Environment Venue Specification. |
| RE Data Out | Parameters controlling all A/V experiential elements including lighting, rigging, FX, audio, video, and cameras/microphones. The actual format used is specified by the Real Environment Venue Specification. |
| RE Commands | Commands controlling for all A/V experiential elements including lighting, rigging, FX, audio, video, and cameras/microphones. The actual format used is specified by the Real Environment Venue Specification. |
4. Functions of AI Modules
Table 2 specifies the Function of the AI Modules.
Table 2 – Functions of AI Modules
| AI Module | |
| Environment Description | Process RE Data In and VE Data In and converts them into Performance Descriptors, Participant Descriptors, and Operator Descriptors using the RE Venue Specification and VE Venue Specification. |
| Performance Status Interpretation | Interprets the Performance Descriptors to produce the Performance Status, consisting of status elements relevant to the current Cue Point conditions which are used by Action Descriptor Generation to identify the next Cue Point of the Script. |
| Participant Status Interpretation | Interprets the Participant Descriptors to produce the Participant Status, consisting of status elements relevant to the current Cue Point conditions which are used by Action Descriptor Generation to identify the next Cue Point of the Script. |
| Operator Command Interpretation | Interprets the Operator Descriptors to produce the Operator Status, consisting of status elements relevant to the current Cue Point conditions which are used by Action Descriptor Generation to identify the next Cue Point of the Script. |
| Action Descriptor Generation | Uses Performance Status, Participant Status, and Operator Status to determine the next Cue Point and output Action Descriptors that describe the Actions necessary to create the complete experience in accordance with the Script. |
| VE Experience Generation | Processes Action Descriptors and produces VE Commands and VE Data Out to the Virtual Environment in accordance with the VE Venue Specification. |
| RE Experience Generation | Processes Action Descriptors and produces RE Commands and RE Data Out to the Real Environment in accordance with the RE Venue Specification. |
5. Input/output Data of AI Modules
Table 2 specifies the Function of the AI Modules.
Table 2 – Functions of AI Modules
6. AIW, AIMs, and JSON Metadata
Table 4 provides the links to the AIW and AIM specifications and to the JSON syntaxes. AIMs/1 indicates that the column contains Composite AIMs and AIMs indicates that the column contains their Basic AIMs.
Table 4 – AIW, AIMs, and JSON Metadata
| AIM | AIMs | Name | JSON |
| XRV-LTP | Live Theatrical Performance | X | |
| XRV-END | Environment Description | X | |
| XRV-PFI | Performance Status Interpretation | X | |
| XRV-PTI | Participant Status Interpretation | X | |
| XRV-OCI | Operator Command Interpretation | X | |
| XRV-ADG | Action Descriptor Generation | X | |
| XRV-VEG | VE Experience Generation | X | |
| XRV-REG | RE Experience Generation | X |