1 Scope of Conversation with Emotion
2 Reference Architecture of Conversation with Emotion
3 I/O Data of Conversation with Emotion.
4 Functions of AI Modules of Conversation with Emotion
5 I/O Data of AI Modules of Conversation with Emotion
6 JSON Metadata of Conversation with Emotion
1 Scope of Conversation with Emotion
In the Conversation with Emotion (MMC-CWE) Use Case, a machine responds to a human’s textual and/or vocal utterance in a manner consistent with the human’s utterance and emotional state, as detected from the human’s text, speech, or face. The machine responds using text, synthetic speech, and a face whose lip movements are synchronised with the synthetic speech and the synthetic machine emotion.
2 Reference Architecture of Conversation With Emotion
Figure 1 gives the Reference Model of Conversation With Emotion including the input/output data, the AIMs, the AIM topology, and the data exchanged between and among the AIMs.
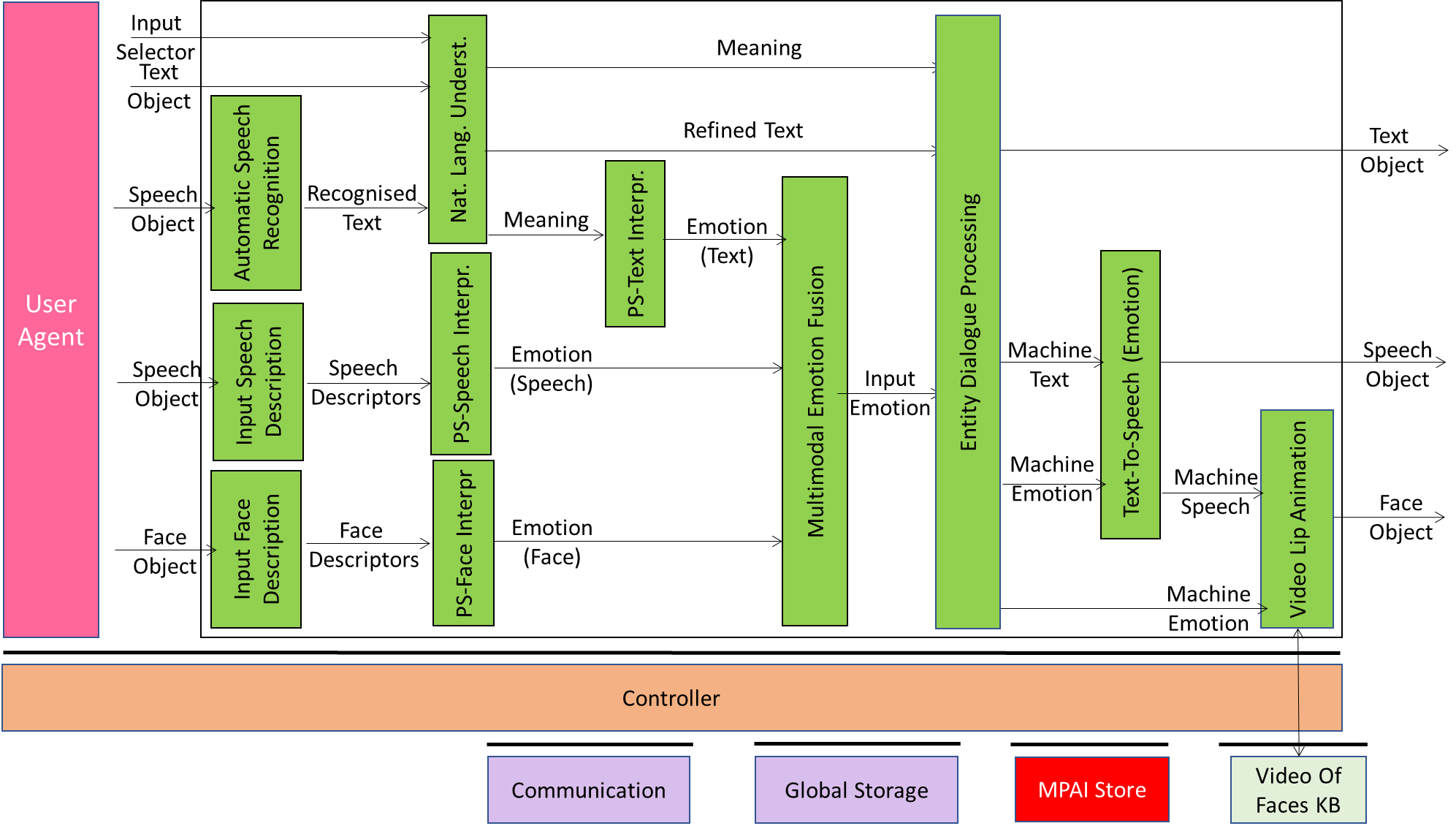
Figure 1 – Reference Model of Conversation With Emotion
The operation of Conversation with Emotion develops as follows:
- Automatic Speech Recognition produces Recognised Text
- Input Speech Description and PS-Face Interpretation produce Emotion (Speech).
- Input Face Description and PS-Face Interpretation produce Emotion (Face).
- Natural Language Understanding refines Recognised Text and produces Meaning.
- Input Text Description and PS-Text Interpretation produce Emotion (Text).
- Multimodal Emotion Fusion AIM fuses all Emotions into the Fused Emotion.
- The Entity Dialogue Processing AIM produces a reply based on the Fused Emotion and Meaning.
- The Text-To-Speech (Emotion) AIM produces Output Speech from Text with Emotion.
- The Lips Animation AIM animates the lips of a Face drawn from the Video of Faces KB consistently with the Output Speech and the Output Emotion.
3 I/O Data of Conversation with Emotion
The input and output data of the Conversation with Emotion Use Case are:
Table 1 – I/O Data of Conversation with Emotion
| Input | Descriptions |
| Input Selector | Data determining the use of Speech vs Text. |
| Text Object | Text typed by the human as additional information stream or as a replacement of the speech depending on the value of Input Selector. |
| Speech Object | Speech of the human having a conversation with the machine. |
| Face Object | Visual information of the Face of the human having a conversation with the machine. |
| Output | Descriptions |
| Text Object | Text of the Speech produced by the Machine. |
| Speech Object | Synthetic Speech produced by the Machine. |
| Face Object | Video of a Face whose lip movements are synchronised with the Output Speech and the synthetic machine emotion. |
4 Functions of AI Modules of Conversation with Emotion
Table 2 provides the functions of the Conversation with Emotion AIMs.
Table 2 – Functions of AI Modules of Conversation with Emotion
| AIM | Function |
| Automatic Speech Recognition | 1. Receives Speech Object. 2. Produces Recognised Text. |
| Input Speech Description | 1. Receives Speech Object. 2. Produces Speech Descriptors |
| Input Face Description | 1. Receives Face Object. 2. Extracts Face Descriptors. |
| Natural Language Understanding | 1. Receives Input Selector, Text Object, Recognised Text. 2. Produces Meaning (i.e., Text Descriptors), Refined Text. |
| PS-Speech Interpretation | 1. Receives Speech Descriptors. 2. Provides the Emotion of the Face. |
| PS-Face Interpretation | 1. Receives Face Descriptors. 2. Provides the Emotion of the Face. |
| PS-Text Interpretation | 1. Receives Text Descriptors. 2. Provides the Emotion of the Text. |
| Multimodal Emotion Fusion | 1. Receives Emotion (Text), Emotion (Speech), Emotion (Face). 2. Provides human’s Input Emotion by fusing Emotion (Text), Emotion (Speech), and Emotion (Video). |
| Entity Dialogue Processing | 1. Receives Refined Text, Meaning, Input Emotion. 2. Analyses Meaning and Input Text or Refined Text, depending on the value of Input Selector. 3. Produces Machine Emotion and Machine Text. |
| Text-to-Speech | 1. Receives Machine Text and Machine Emotion. 2. Produces Output Speech. |
| Video Lip Animation | 1. Receives Machine Speech and Machine Emotion. 2. Animates the lips of a video obtained by querying the Video Faces KB, using the Output Emotion. 3. Produces Face Object with synchronised Speech Object (Machine Object). |
5 I/O Data of AI Modules of Conversation with Emotion
The AI Modules of Conversation with Emotion perform the Functions specified in Table 21.
Table 3 – AI Modules of Conversation with Emotion
| AIM | Receives | Produces |
| Automatic Speech Recognition | Speech Object | Recognised Text |
| Input Speech Description | Speech Object | Speech Descriptors |
| Input Face Description | Face Object | Face Descriptors |
| Natural Language Understanding | Recognised Text | Refined Text Text Descriptors |
| PS-Speech Interpretation | Speech Descriptors | Emotion (Speech) |
| PS-Face Interpretation | Face Face Descriptors | Emotion (Face) |
| PS-Text Interpretation | Text Descriptors | Emotion (Text) |
| Multimodal Emotion Fusion | Emotion (Text) Emotion (Speech) Emotion(Face) |
Input Emotion |
| Entity Dialogue Processing | 1. Text Descriptors 2. Based on Input Selector 2.1. Refined Text 2.2. Input Text 3. Input Emotion |
1. Machine Text 2. Machine Emotion |
| Text-to-Speech | 1. Machine Text 2. Machine Emotion |
Output Speech. |
| Video Lip Animation | 1. Machine Emotion 2. Machine Speech |
Output Visual |
6 Specification of Conversation with Emotion AIMs and JSON Metadata
Table 4 – AIMs and JSON Metadata
| AIMs | Name | JSON | |
| MMC-CWE | Conversation With Emotion | X | |
| – | MMC-ASR | Automatic Speech Recognition | X |
| – | MMC-ISD | Input Speech Description | X |
| – | PAF-IFD | Input Face Description | X |
| – | MMC-NLU | Natural Language Understanding | X |
| – | MMC-PSI | PS-Speech Interpretation | X |
| – | PAF-PFI | PS-Face Interpretation | X |
| – | MMC-PTI | PS-Text Interpretation | X |
| – | MMC-MEF | Multimodal Emotion Fusion | X |
| – | MMC-EDP | Entity Dialogue Processing | X |
| – | MMC-TTS | Text-to-Speech | X |
| – | MMC-VLA | Video Lip Animation | X |