Function
Ref. Model
I/O Data
SubAIMs
JSON MData
Profiles
Ref. Software
Conformance
Performance
1 Functions
The Context Enhancement (PGM‑CXE) AIM performs interpretative enrichment and cross‑modal analysis of a captured media scene in order to produce:
- enhanced descriptions of the audio and visual scene, and
- an interpreted description of the User State.
Context Enhancement operates on time‑synchronised perceptual descriptors produced by Context Capture and applies modality‑specific analysis, cross‑modal alignment, and optional domain knowledge to derive evidence and state descriptions suitable for downstream reasoning and control.
2 Reference Model
Figure 1 depicts the Reference Model of the Context Enhancement (PGM‑CXE) AIM.
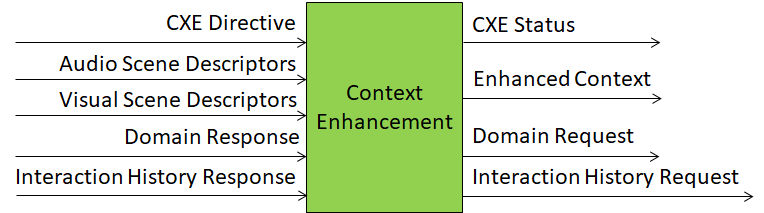
Figure 1 – Reference Model of the Context Enhancement (PGM‑CXE) AIM
3 I/O Data
Table 1 specifies the Input and Output Data of the Context Enhancement (PGM‑CXE) AIM.
| Input | Description |
|---|---|
| Audio Scene Descriptors (ASD0) | Perceptual description of the audio scene produced by Context Capture. |
| Visual Scene Descriptors (VSD0) | Perceptual description of the visual scene produced by Context Capture. |
| CXE Directive | Control directives from A‑User Control specifying scope, depth, or policy constraints for CXE processing concerning Audio, Visual, and User. |
| Domain Response | Domain‑specific knowledge received from Domain Access. |
| Output | Description |
| Enhanced Context | Aggregated result combining Enhanced Audio and Visual Scene Descriptors and User Entity State. |
| Domain Request | Request for domain‑specific knowledge sent to Domain Access. |
| CXE Status | Status information describing the execution and outcome of CXE processing. |
4 SubAIMs (informative)
This section is informative. The decomposition into SubAIMs described below illustrates one conformant architecture for producing the normative outputs of PGM‑CXE. Implementations may adopt alternative internal structures provided they satisfy the conformance requirements of Section 8.
4.1 Reference Model
Figure 1 gives the Reference Model of the Context Enhancement (PGM‑CXE) Composite AI Module implementing the Context Enhancemeent functionality.
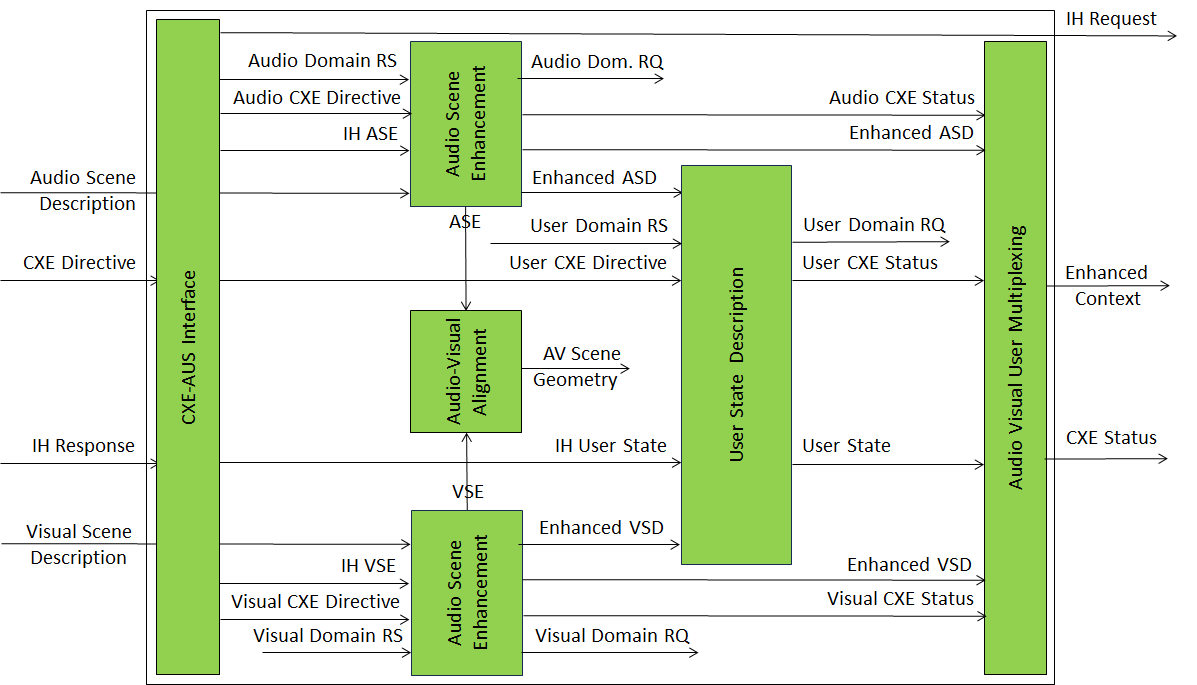
Figure 2 – Reference Model of the Context Enhancement (PGM‑CXE) Composite AIM
4.2 Operation
The CXE operation is carried out with the following steps:
- Reception of
- CXE Directive from A-User Control.
- Audio Scene Descriptors and Visual Scene Descriptors from Context Capture.
- Interaction History from A-User Storage.
- Audio, Visual and User Domain Responses.
- Enhancement of Audio and Visual Scene Descriptors and Audio-Visual Alignment.
- Production of User State Description
- Production of Audio, Visual, and User State Statuses
- Production of Enhanced Context and CXR Stats.
The reference model explicitly separates capture, modal enhancement, cross‑modal alignment, and user/entity interpretation, ensuring modularity, traceability, and reuse.
4.3 Functions of SubAIMs
Table 2 specifies the functions of the Context Enhancement (PGM‑CXE) SubAIMs.
| SubAIM | Function |
|---|---|
| Audio Scene Enhancement | Enhances the description of the Audio Scene. |
| Visual Scene Enhancement | Enhances the description of the Visual Scene. |
| Audio‑Visual Alignment | Cross‑modal association between Audio Objects and Visual Objects referring to the same source or entity. Production of Audio‑Visual Scene Geometry expressing correspondence and spatial relations. |
| User State Description | Interpretation of enhanced descriptors and alignment evidence with respect to the User or other entities. Derivation of User‑centric evidence and state descriptions under the control of directives (User Entity State). |
| Audio‑Visual‑User Multiplexing | Consolidation of enhanced scene descriptors and User‑related outputs into a coherent Enhanced Context. Generation of status information describing the outcome of CXE processing. |
4.4 I/O Data of SubAIMs
Table 3 gives the Input and Output Data of the Context Enhancement (PGM‑CXE) SubAIMs.
Table 3 gives the Input and Output Data of the Context Enhancement (PGM‑CXE) SubAIMs.
4.5 AIMs and JSON Metadata
Table 4 provides the links to the AIM specifications and JSON schemas. AIM1 indicates the Composite AIM and AIM2 its SubAIMs.
| AIM1 | AIM2 | Name | JSON |
|---|---|---|---|
| PGM‑CXE | Context Enhancement | X | |
| PGM‑ASE | Audio Scene Enhancement | X | |
| PGM‑VSE | Visual Scene Enhancement | X | |
| OSD‑AVA | Audio‑Visual Alignment | X | |
| PGM‑USD | User State Description | X | |
| PGM‑MUX | Audio‑Visual‑User Multiplexing | X |
5 JSON Metadata
https://schemas.mpai.community/PGM1/V1.0/AIMs/ContextEnhancement.json
6 Profiles
No Profiles.
7 Reference Software
Not part of this specification.
8 Conformance Testing
Table 5 provides the Conformance Testing Method for the Context Enhancement (PGM‑CXE) AIM. Conformance Testing of the individual SubAIMs is given by the individual AIM specifications.
If a schema contains references to other schemas, conformance of data for the primary schema implies that any data referencing a secondary schema shall also validate against the relevant schema, if present, and conform with the Qualifier, if present.
| Receives | Audio Scene Descriptors | Shall validate against Audio Scene Descriptors schema. |
| Visual Scene Descriptors | Shall validate against Visual Scene Descriptors schema. | |
| CXE Directive | Shall validate against CXE Directive schema. | |
| Domain Response | Shall validate against Domain Response schema. | |
| Produces | Enhanced Context | Shall validate against Enhanced Context schema. |
| Domain Request | Shall validate against Domain Request schema. | |
| CXE Status | Shall validate against CXE Status schema. |
9 Performance Assessment
Not part of this specification.