| <–Visual humans and machines | Audio for humans--> |
| 7.1 | Question Answering (QA) |
| 7.2 | Dialog Processing |
| 7.3 | Deep Learning Language Model |
In recent years, the development of AI-based systems for providing human-friendly services based on human understanding has been steadily progressing. The main technology of such AI systems can be called language intelligence technology. This allows users to communicate desired knowledge expressed in words while accessing services, or to acquire and communicate the same knowledge without being confined to a specific language. The realization of language intelligence technology for communication and knowledge acquisition is expected to make human life more convenient.
Lexical and sentence grammar analysis used in ML/deep learning-based Natural Language Processing (NLP) and Question Answering (QA) are making AI-based natural language understanding successful in commercial services. Today, various language intelligence-based systems and services are employed in intelligent information services applications.
Speech interface technology fundamentally expands the way humans interact with machines. For example, the field of machine-based professional counselling services aims to reach the level of counselling that an expert human can provide using speech recognition, conversation processing and knowledge mining. Through this, full-fledged interactive AI-based services (e.g., unmanned AI-based call centre, AI shopping host, etc.) are possible, and they can also be used for public services such as 24-hour counselling for the socially marginalized elderly and youth, and for soldiers needing help.
The speech interface can be expanded to other knowledge processing areas by recognising variously acquired emotions and situations, merging them with speech and linguistic intelligence, and mapping visual and other types of information to a unified knowledge space.
Speech and language are the most natural communication means for humans and language intelligence is the AI technology that enables machines to recognize, understand, and generate meaning out of speech. AI-based language intelligence is making it possible for machines to understand content, learn, think, and reason much like a human.
7.1 Question Answering (QA)
QA is an intelligent function that generates answers to a user’s question in a natural language. In the future, more and more systems will be equipped with QA functions for a better user experience. Currently, the most widely used QA system is an intelligent agent provided in smart phones. This is not a completely intelligent agent able to answer all questions that users may ask, and more domain-specific QA services would be useful.
Figure 6 presents an example of the functional blocks of a QA system architecture. A traditional QA system consists of several functional blocks: natural language processing (NLP), question analysis, candidate answer generation, answer inference and answer generation.
Natural language QA is a technology that proposes correct answer candidates to a user’s natural language question and selects and presents an optimal answer among them. Natural language QA technology consists of the following core technologies.
Structure/semantic analysis understands the contents of a natural language text by means of syntax analysis, and semantic analysis such as named entity recognition.
Question analysis and understanding classifies and recognizes questions.
Open knowledge extraction generates pre-defined data structures filled with the results of syntax analysis or semantic role assignment for Big Data processing. It includes extracting knowledge by identifying subjects and objects of sentences using only text.
Knowledge to KB linking technology compares the knowledge extracted from the text with the knowledge existing in the KB, analyses the truth, redundancy, and plausibility of knowledge, and finally decides whether to delete or keep it.
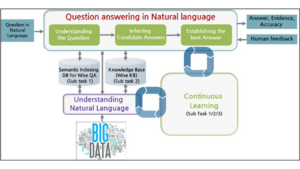
Figure 6 – Example of functional blocks in QA architecture
Candidate answer generation searches for effective documents/paragraphs, extracts correct answer candidates from related paragraphs, and calculates reliability for each candidate answer.
Best answer selection performs answer inference based on feature normalization and ranking of candidate answers and best answer generation on the terminal.
Neural network approach for QA
The neural network approach to QA systems is gradually introduced replacing some modules of the traditional data processing-based QA systems.
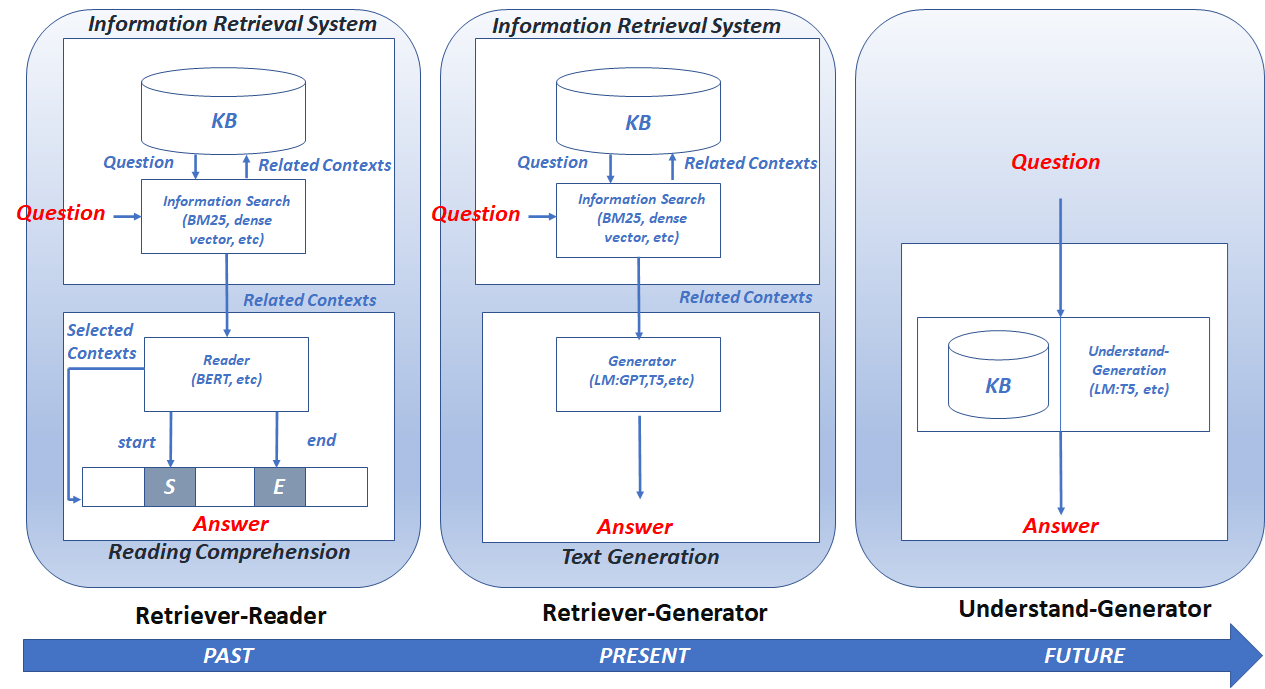
Figure 7 – Three types of open-domain question answering[1]
The classification introduced by [5] shows different types of open-domain questions in increasing order of difficulty that a NN can answer:
- The question and answer have been seen at training time.
- The question was not seen at training time, but the answer was.
- Neither the question nor the answer was seen at training time.
7.2 Dialog Processing
Natural language dialogue processing includes conversation understanding technology to determine the intention of the questioner, dialogue modelling technology for generating natural dialogues, and dialogue error correction. The last is relevant to foreign language learning applications.
Traditional dialogue systems are based on a modular data processing architecture and their workflow is as follows: the natural language processing module identifies user intention and extracts task-specific knowledge, and the dialogue state tracking module tracks the user goal considering dialogue history. The system can obtain the belief state for comparison with the database, such as finding the number of matching entities. Based on the information, the dialogue policy module determines the next system action and then the language generation module generates an appropriate response matching the system action.
With the progress of NNs, recent work on dialog systems handles individual modules in a unified way. The approach end-to-end dialog processing is to train a model with users’ utterance sentences, so that the system generates a response suitable for given purposes, contexts, and situations. This has shown very promising results. Such models are typically developed by fine-tuning the large pre-trained models.
Another approach that leverages knowledge transfer is multi-task learning. The goal is to learn common knowledge representations between related tasks. It has been shown that multi-task learning not only improves NN performance, but also mitigates the problem of overfitting, i.e., the case when the training was made to match too closely a particular set of data and may therefore be inadequate to make reliable predictions. Both approaches are complementary and combing them improves the performance of natural language understanding.
End-to-End Dialog Processing
For the dialog processing subsystem to generate a system response suitable for its purpose, various learning methods are required such as transfer learning, semi-supervised dialog knowledge extraction, longitudinal supervised learning, self-conversational reinforcement learning, text processing, query generation, and text understanding. As a result of this learning, NN DBs for end-to-end dialogue model knowledge and domain dialogue knowledge are built. A system response is made by the end-to-end conversational processing produced using these NN DBs.
The end-to-end dialog processing decoder produces an appropriate system response according to the current situation. It uses structured or unstructured domain knowledge and the dialog history of the prior system and user utterances up to the current turn. In addition to generating relevant system responses, the dialog processing decoder can process out-of-domain utterances. That is, it can generate a natural system utterance in response to the user’s non-domain utterance, and then return to the original goal-oriented dialog.
7.3 Deep Learning Language Model
Language models are those that assign probabilities to sequences of words for word prediction. Statistical Language Models use traditional statistical techniques like N-grams, Hidden Markov Models (HMM) and certain linguistic rules to learn the probability distribution of words. Neural Language Models use different kinds of Neural Networks to model language and have better performance and effectiveness than statistical language models. The Deep Learning language model is a pre-trained NN built from a large text data set for general-purpose semantic expressions that can be used for various tasks. To learn universal semantic expressions from text Big Data, self-supervised learning tasks such as predicting a blank or the next word are used. In these cases, a human can find a correct answer without a separate correct answer being previously labelled. The deep learning language NN has recently been used as a base NN for various language processing tasks such as language understanding and language generation.
Transformer Model
The deep learning language model mainly uses the transformer model that has advanced the state of the art in many Natural Language Processing (NLP) tasks. The structure of the transformer model is shown in Figure 8. It consists of an encoder part (left), and a decoder part (right) with stacked self-attention and pointwise, fully connected layers for both the encoder and decoder, shown in the left and right halves of Figure 8, respectively.
The transformer model, originally proposed in the field of machine translation, consists of an encoder part (left) that expresses the input text in the deep learning space, and a decoder part (right) that predicts the next word using the input text and previous output results. The encoder and decoder consist of 2 main modules: first module is to select a nearby word important for blank word prediction or to select previous words important for next word prediction using a self-attention mechanism. The second module is to calculate a deep expression using a NN using a two-layer feed-forward neural network (FFNN). Compared with CNNs and RNNs, the transformer model can reflect information by directly calculating the relationship between a plurality of words that have an important relationship with each other and can be easily parallelized. Therefore, the technology is gradually expanding not only in the field of language processing but also in the field of vision.
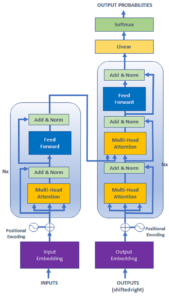
Figure 8 – Structure of Transformer Model [6]
There are 3 types of deep learning language models: encoder-based models, decoder-based models, and encoder-decoder-based models. The language model that pre-trained the encoder of the transformer using bulk text is a BERT-series language model, and the model that pre-trained the decoder is a Generative Pre-trained Transformer (GPT)-series language model. It includes the raised GPT-3 model. T5 and BART are examples of pre-trained models using the transformer’s encoder and decoder together.
Encoder-based Language Model
The BERT series language model shows excellent performance in various language understanding tasks such as machine reading, document classification, language analysis, and search result ranking. This model has the most follow-up and application studies among pre-learning language models. However, it has several disadvantages: it is not easy to use for language generation type tasks such as summary and dialogue processing, and it is necessary to add a task-specific layer when applied to a specific application task. The addition of task-specific layers makes it difficult to learn multi-tasks. Even if a very large BERT language model is built, if a new task-specific layer cannot be learned with a small number of learning examples, few-shot learning like GPT-3 will be difficult.
Decoder-based Language Model
The GPT model uses the decoder structure of the transformer and predicts the next word by using the previous word information for each word. GPT-3 increases the size of the GPT model to 175 billion. It shows that a sufficiently large and large-capacity language model is capable of few-shot learning. To prove that few-shot learning is possible, GPT-3 tested various fields such as news article generation, QA, machine reading, translation, and virtual tasks, and measured the few-shot learning performance by model size in each experiment.
GPT-3 has shown that the 175 billion-scale model can be quickly generalized like the few-shot learning. Especially in the case of news article generation, it is possible to create an article that humans can hardly distinguish from an article written by a human.
However, it is not clear whether the language model has solved the few-shot learning through actual reasoning, or the task was solved by the pattern recognition result of the pre-learning stage. GPT-3 still repeats or contradicts similar words when generating articles. There are limitations in the fact that it generates texts that show low performance in semantic comparison tasks, does not reflect video and real-world physical interactions, and requires high costs in the learning and application stages. In addition, the GPT series model performs only one-way operation on input sentences, and the fact that it shows low performance compared to the model size in the machine reading comprehension task is a limitation to its utilization.
Encoder-Decoder-based Language Model
There is a pre-learning language model that uses both a transformer encoder and a decoder, the T5 model, which shows a universal input/output framework that receives text as input and outputs text as a result. Structurally, the T5 model includes both encoder and decoder, and has the advantage of showing excellent performance in language comprehension tasks such as machine reading and sentence classification, and language generation tasks such as summary and translation. And, unlike BERT, using a text-to-text general-purpose input/output framework, separate task-specific layer learning for each application task is unnecessary and natural multi-task learning is possible. The T5 model requires 10% additional computation compared to the BERT and GPT single models because it requires intensive computation with the encoder result in the decoder structure. When a specific task such as machine reading is the goal, it has a disadvantage that the performance is not excellent compared to the BERT series model with the same amount of computation.
Issues on Language Model
Although the deep learning pre-trained language model is being used as a base model in various language processing tasks such as language understanding and language generation, it still has many limitations. For example, the current pre-learning technology requires tens to hundreds of times more learning data than text that humans see throughout their life. Another issue is that all knowledge is implicitly stored in real values in the deep learning model, and there is no learning about real-world physical interactions. It is expected that these limitations can be overcome through future studies such as improvement of sample efficiency in the learning process, model structure that can utilize external knowledge, and learning that reflects other modalities such as video.
[1] https://lilianweng.github.io/lil-log/2020/10/29/open-domain-question-answering.html
| <–Visual humans and machines | Audio for humans--> |