| <–Divide and conquer | Structure of MPAI standards–> |
Many experts have participated in the development of MPAI data coding standards. In 15 months, MPAI has been able to develop three data coding standards:
Multimodal Conversation (MPAI-MMC): 5 use cases
Context-based Audio Enhancement (MPAI-CAE): 4 use cases
Compression and Understanding of Industrial Data (MPAI-CUI): 1 use case
Notwithstanding its short existence (established in September 2020), MPAI has already been able to publish results on its standard work at major conferences [26, 27, 28].
In the following, their work will be condensed in a few sentences and one figure. Those wishing to have a more in-depth understanding of the work done should study the standards publicly available for download (https://mpai.community/standards/resources/).
| 13.1 | Conversation with emotion |
| 13.2 | Conversation about an object |
| 13.3 | Feature-preserving speech translation |
| 13.4 | Emotion enhanced speech |
| 13.5 | Speech restoration system |
| 13.6 | Audio recording preservation |
| 13.7 | Enhanced audioconference experience |
| 13.8 | Company performance prediction |
13.1Conversation with emotion
Humans use a variety of modalities based on social conventions to communicate with other humans. The same words of a written sentence can place different emphasis, if put in different order, or even mean different things. A verbal utterance can be substantially complemented by intonation, colour, emotional charge etc. The receiver of the message may even get an utterance having widely different meanings compared to what the actual words without emphasis would mean otherwise. In some cases what words say can even be at odds with what eyes, mouth, face, and hands express over and beyond what words say.
Conversation with emotion (CWE) is a use case of the MPAI Multimodal Conversation (MPAI-MMC) standard providing a comprehensive human-machine conversation solution. Different media used by a human help the machine fine-tune its response to a human vocal utterance thanks to its ability to understand – from speech and face – human’s intention and meaning. The response of the machine can then be suitably expressed with different complementary media.
-
The machine’s Speech Recognition AIM, Language Understanding AIM and Video Analysis AIM recognise the emotion embedded in speech and video.
-
The Emotion Fusion AIM fuses all Emotions into the Final Emotion.
-
The Dialog Processing AIM produces a reply based on the Final Emotion and Meaning from the text and video analysis.
-
The Speech Synthesis (Emotion) AIM produces Output Speech from Text with Emotion.
-
The Lips Animation AIM animates the lips of a Face drawn from the Video of Faces Knowledge Base consistently with the Output Speech.
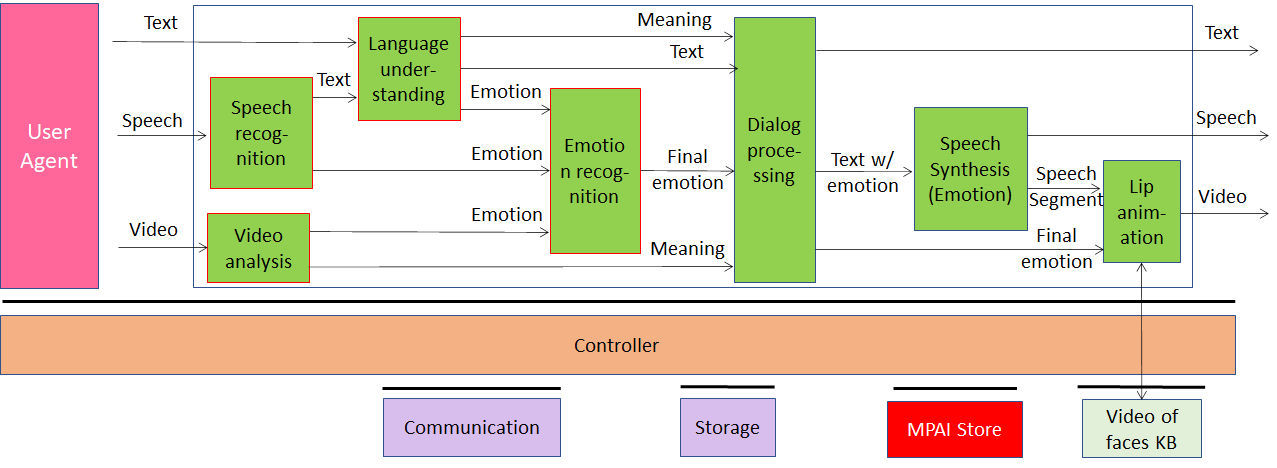
Figure 15 – Conversation with Emotion
This use case specifies function and interfaces of several reusable AIMs:
-
Speech Recognition where the output is text and emotion.
-
Video Analysis that extracts emotion and meaning from a human face.
-
Language Understanding that extracts meaning from text.
-
Emotion Fusion that fuses emotions extracted from speech and video.
-
Dialogue Processing that provides an emotion-enhanced text in response to text, emotion and meanings from text and video.
-
Speech Synthesis producing emotion enhanced speech from text and emotion.
-
Lips Animation producing video from speech and emotion.
Future work will open the scope of the technologies implied by the current selection of data formats and will address conversation about a scene and conversation with an autonomous vehicle. These are shortly described in Chapter 19.
13.2Conversation about an object
Multimodal Question Answering (MQA) is a use case of the MPAI-MMC standard whose goal is to enable a machine to provide a response to a human asking a question using natural language about the object held in their hand and the machine answer to the question with synthesised speech (Figure 16). Question and image are recognised and analysed in the following way and answers are produced in the output speech:
-
The machine’s Video Analysis AIM analyses the input video and identifies the object in the vide producing the name of the object in focus.
-
The Speech Recognition AIM analyses the input speech and generates text output.
-
The Language Understanding AIM analyses natural language expressed as text using a language model to produce the meaning of the text.
-
The Question Analysis AIM Analyses the meaning of the sentence and determines the Intention
-
The Question Answering AIM analyses user’s question and produces a reply based on user Intention.
-
The Speech Synthesis (Text) AIM produces Output Speech from Text in the reply.
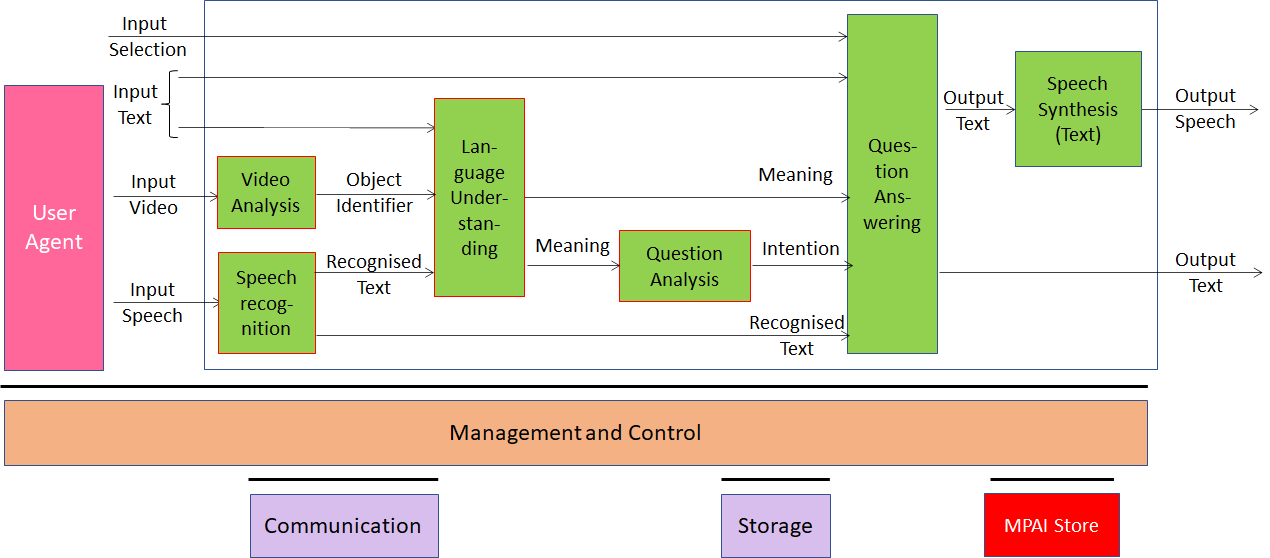
Figure 16 – Conversation about an object
This use case specifies function and interfaces of several reusable AIMs:
-
Video Analysis that extracts object identifier from the input video.
-
Speech Recognition where the output is text.
-
Language Understanding that extracts meaning from text integrated with the object name.
-
Question Analysis that extracts intention from the text with meaning.
-
Question Answering that provides a reply in text in response to text, intention and meanings from text and video.
-
Speech Synthesis (Text) producing speech from text.
13.3Feature-preserving speech translation
Unidirectional Speech Translation (UST) is a use case of the MPAI-MMC standard enabling a user to obtain a spoken translation of their utterances to a specified language preserving the speaker’s vocal features.
This workflow is designed to
-
Accept speech as input.
-
Convert that speech to text (using a Speech Recognition AIM).
-
Translate that text into text of another language (using the Speech Translation AIM).
-
Analyse the input speech (using the Speech Feature Extraction AIM).
-
Synthesize the translated text as speech that retains specified aspects of the input voice, e.g., timbre (colour) (using the Speech Synthesis (Features) AIM.
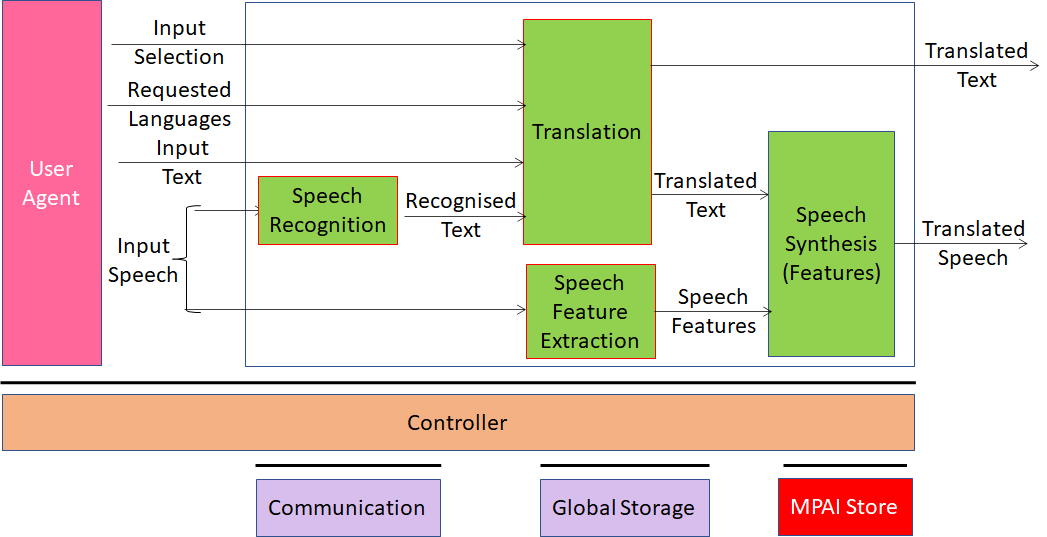
Figure 17 – Feature-preserving speech translation
For the purpose of point 4., the workflow utilizes, in addition to the Speech Recognition module, two more specialized speech-related modules: one – Speech Feature Extraction – extracts relevant speech features from the input speech signal; and another – Speech Synthesis (Features) – can incorporate those features, along with specification of the text to be spoken aloud, when synthesizing. All these modules can be reused in other workflows, and thus exemplify MPAI’s standard module philosophy.
The MPAI-MMC standard supports two additional use cases. Bidirectional Speech Translation combines two flows to enable a bidirectional conversation and One-to-many Speech Translation enables a single speech to be simultaneously translated into a set of languages for distribution to appropriate recipients.
Several other useful configurations are currently subject to research and development and may become additional AIFs before long.
13.4Emotion enhanced speech
Speech carries information not only about its lexical content, but also about several other aspects including age, gender, identity, and emotional state of the speaker. Speech synthesis is evolving towards support of these aspects.
In many use cases, emotional force can usefully be added to speech which by default would be neutral or emotionless, possibly with grades of a particular emotion. For instance, in a human-machine dialogue, messages conveyed by the machine can be more effective if they carry emotions appropriately related to the emotions detected in the human speaker.
Emotion-Enhanced Speech (EES) is a use case of the Context-based Audio Enhancement (MPAI-CAE) standard that enables a user to indicate a model utterance or an Emotion to obtain an emotionally charged version of a given utterance.
CAE-EES implementation can be used to create virtual agents communicating as naturally as possible, and thus improve the quality of human-machine interaction by bringing it closer to human-human interchange.
The CAE-EES Reference Model depicted in Figure 18 supports two modes implemented as pathways enabling addition of emotional charge to an emotionless or neutral input utterance (Emotion-less speech).
-
Along Pathway 1 (upper and middle left in the Figure), a Model Utterance is input together with the neutral Emotionless Speech utterance into the Speech Feature Analyser1, so that features of the former can be captured and inserted into the latter by the Emotion Inserter.
-
Along Pathway 2 (middle and lower left in the Figure), neutral Emotionless Speech utterance is input along with an identifier of the desired Emotion(s). Speech Feature Analyser2 extracts Emotionless Speech Features that describe its initial state from Emotionless Speech and sends them to Emotion Feature Inserter that produces the Speech Features that specify the same utterance as Emotionless Speech, but now with the desired emotional charge. Speech Features are sent to Emotion Inserter, which uses the Speech Features set to synthesize Speech with Emotion.
Emotion-Enhanced Speech, designed for use in entertainment and communication, exploits the technology for creation of embeddings within vector spaces that can represent speech features conveying emotions. It’s designed to enable addition of emotional features to a bland preliminary synthetic speech segment, thus enabling the artificial voice to perform – to act!
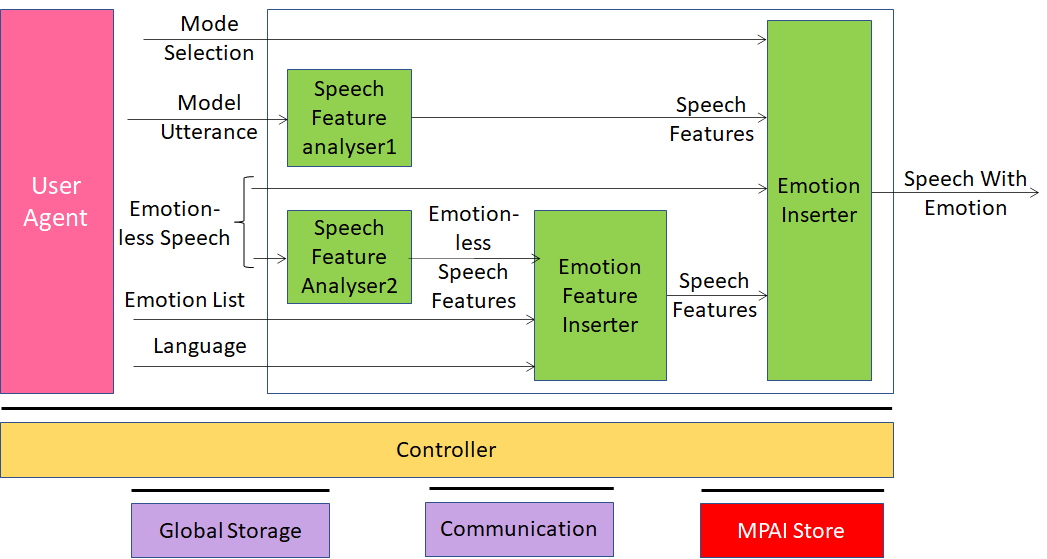
Figure 18 – Emotion enhanced speech
13.5Speech restoration system
The goal of the Speech Restoration System (SRS) use case of the MPAI-CAE standard is to restore a damaged segment of an audio segment containing speech from a single speaker. An AIM is trained to create a NN-based speech model of the speaker. This model is used by a speech synthesiser which receives the text of the damaged segment and produces the synthetic version of the damaged speech. The Assembler replaces the damaged segment.
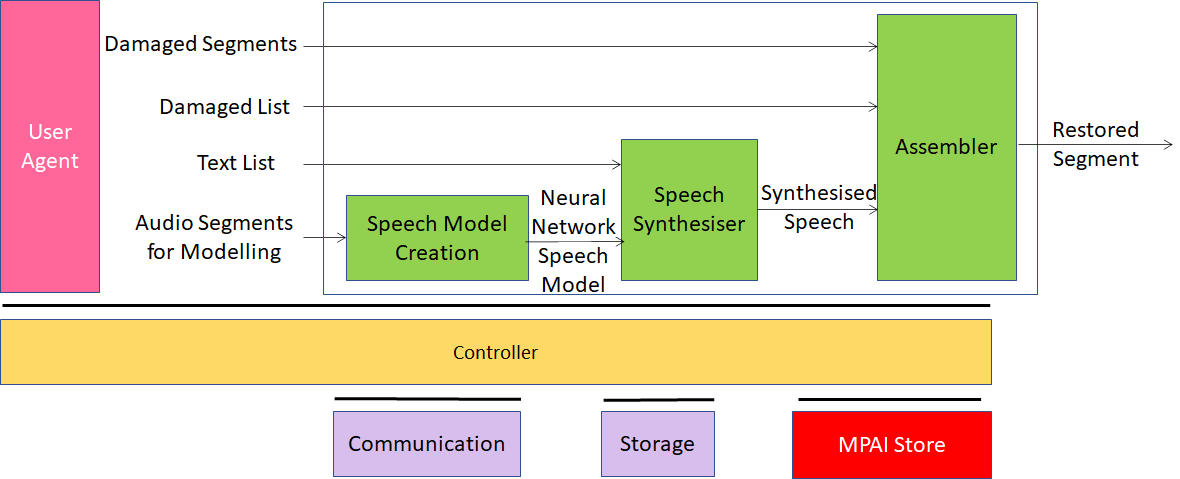
Figure 19 – Speech restoration system
13.6Audio recording preservation
For many international audio archives, there is an urgent need to digitise all their records, especially analogue magnetic tapes, which have a short life expectancy, especially when compared to paper records. Although international institutions (e.g., International Association of Sound and Audiovisual Archives, IASA; World Digital Library, WDL; Europeana) have defined several guidelines (not always fully compatible with each other), there is still a lack of international standards.
The introduction of this MPAI use case in the field of active preservation of audio documents opens the way to effectively respond to the methodological questions of reliability with respect to the recordings as documentary sources, while clarifying the concept of “historical faithfulness”. In the magnetic tape case, the carrier may hold important information: multiples splices; annotations (by the composer or by the technicians) and/or display several types of irregularities (e.g., corruptions of the carrier, tape of different colour or chemical composition).
The Audio Recording Preservation (ARP) use case of the MPAI-CAE standard focuses on audio read from magnetic tapes, digitised and fed into a preservation system.
Audio data is supplemented by the data from a video camera pointed to the head reading the magnetic tape. The output of the restoration process is composed by a preservation master file that contains the high-resolution audio signal and several other information types created by the preservation process. The goal is to cover the whole “philologically informed” archival process of an audio document, from the active preservation of sound documents to the access to digitised files.
Cultural heritage is one of the fields where AI can have a significant impact. This technology can drastically change the way we preserve, access, and add value to heritage, making its safeguarding sustainable. Audio archives are an important part of this heritage, but require relevant resources in term of people, time, and funding.
CAE-ARP provides a workflow for managing open-reel tape audio recordings. It is an important example of how AI can drastically reduce the resources necessary to preserve and make accessible analogue recordings.
A concise description of the operation of the ARP workflow of Figure 20 is given by:
-
The Audio Analyser and Video Analyser AIMs analyse the Preservation Audio File (a high-quality audio signal) and the Preservation Audio-Visual File [29].
-
All detected irregularity events for both Audio and Image are sent to the Tape Irregularity Classifier AIM, which selects the most relevant for restoration and access.
-
The Tape Audio Restoration AIM uses the retained irregularity events to correct potential errors occurred at the time the audio signal was converted from the analogue carrier to the digital file.
-
The Restored Audio File, the Editing List (used to produce the Restored Audio File, the Irregularity Images, and the Irregularity File containing information about irregularity events) are inserted in the Packager.
-
The Packager produces the Access Copy Files to be used, as the name implies, to access the audio content and the Preservation Master Files, with the original inputs and data produced during the analysis, used for preservation.
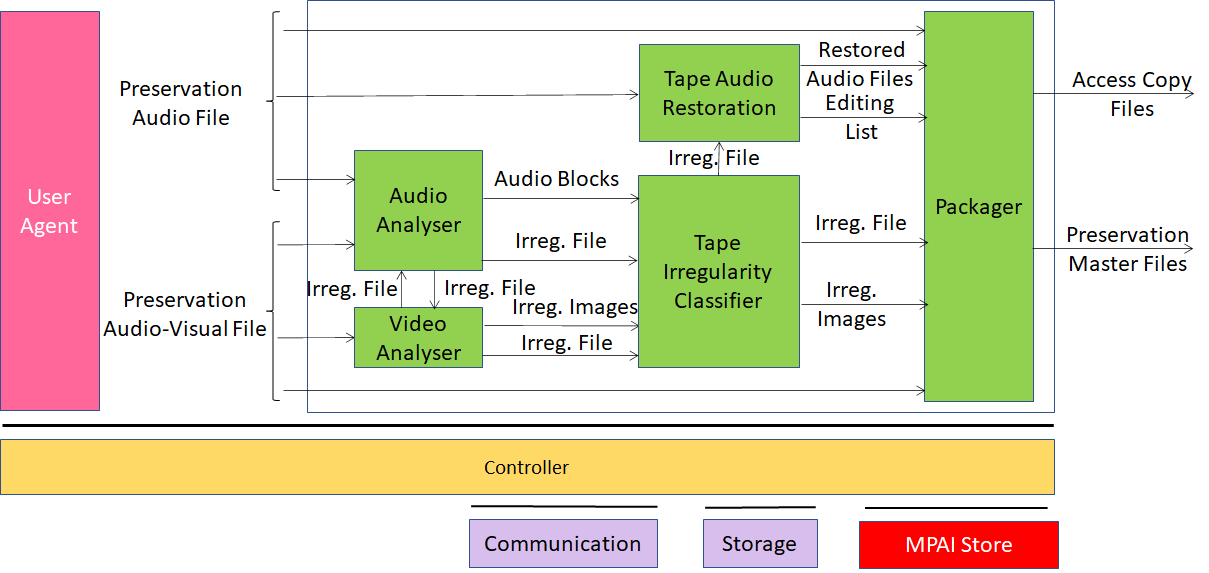
Figure 20 – Audio recording preservation
The overall ARP workflow is complex and involves different competences both in audio and video. Therefore, the MPAI “divide and conquer” approach is well-suited to promote advancement of different algorithms and functionalities because it involves different professionals or companies.
Currently, ARP manages mono audio recordings on open-reel magnetic tape, but the objective is to extend this approach to complex recordings and additional types of analogue carrier such as audiocassettes or vinyl.
13.7Enhanced audioconference experience
How audio for humans is addressed within MPAI can be reviewed by analysing an important use case of the Enhanced Audioconference Experience (EAE) of MPAI-CAE. To connect distant users requires an audio conference application whose quality is limited by the environmental and machine sound conditions. Very often, it is far from satisfactory because of multiple competing speakers, non-ideal acoustical properties of the physical spaces that the speakers occupy and/or background noise. These can lead to reduced-intelligibility speech resulting in distracted or not fully understanding participants, and may eventually lead to what is known as audioconference fatigue.
The main demand from the transmitter side of an audio conference application is to detect the speech and separate it from unwanted disturbances. By using AI-based adaptive noise-cancellation and sound enhancement, those kinds of noise can be virtually eliminated without using complex microphone systems that capture environment characteristics.
Similarly, the experience at the receiver side can be substantially enhanced by spatial presenting speech to offer a more life-like overall experience to the listener. This requires bridging such technology gaps as extracting a spatial of sound fields description, and speech and audio objects from microphone arrays. Transcoding HOA to OBA, generation of HOA and binaural reverberation and individualisation of binaural audio are required technologies [30].
Data-driven or ML based AI used in source separation and noise cancellation can be evaluated by analysing the limitations of the applica-tions. For example, if there is a wide range of noise in the environment, data-driven AI would fail because of limited use of dataset materials for training. In fact, ML-based AI methods can be successfully used to create more robust solutions for these cases.
The reference model of this use case (Figure 21) gets the microphone array audio as input for sound field description. Microphone array geometry also represents the locations of each microphone used for recording the scene. While the perceptual sound field can be represented in 3D hearable angles azimuth and elevation, the limitations over the number of microphones and field coverage for horizontal or vertical planes reduce the performance for the operational environment.
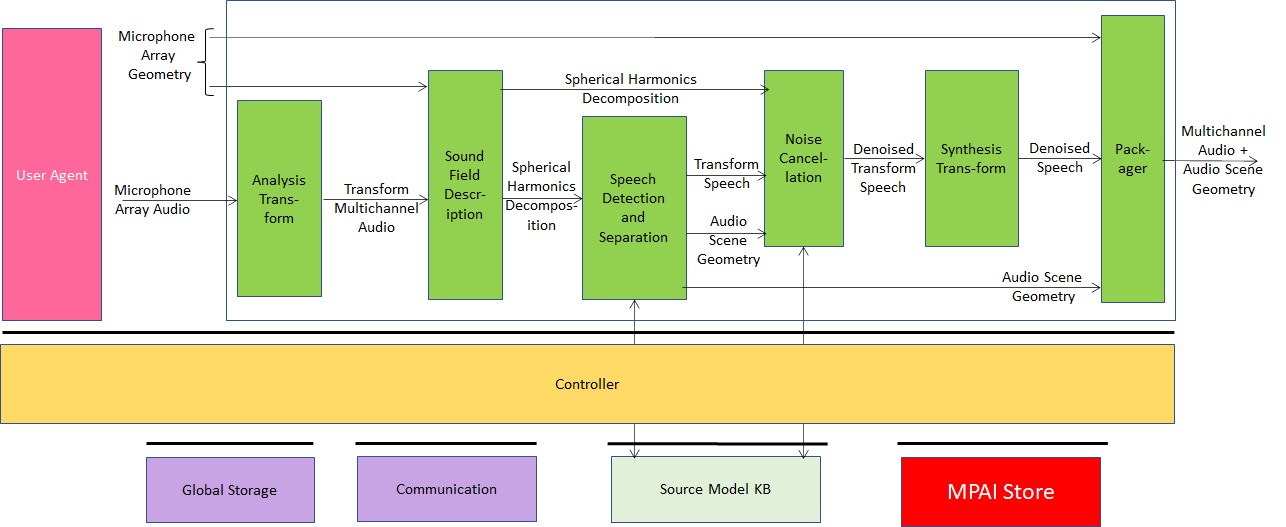
Figure 21 – Enhanced Audioconference Experience
The sequence of EAE operations of the following:
-
Analysis Transform AIM transforms the Microphone Array Audio into fre-quency bands via a Fast Fourier Transform (FFT) to enable the following operations to be carried out in discrete frequency bands.
-
Sound Field Description AIM converts the output from the Analysis Transform AIM into the spherical frequency domain. If the microphone array capturing the scene is a spherical microphone array, Spherical Fourier Transform (SFT) can be used to obtain the Sound Field description that represent the captured sound field in the spatial frequency domain.
-
Speech Detection and Separation AIM receives the sound field description to detect and separate directions of active sound sources. Each separated source can either be a speech or a non-speech signal.
-
Noise Cancellation AIM eliminates audio quality-reducing background noise and reverberation.
-
Synthesis Transform AIM applies the inverse analysis transform on the received Denoised Transform Speech.
-
Packager AIM
-
Receives Denoised Speech and Audio Scene Geometry.
-
Multiplexes the Multichannel Audio stream and the Audio Scene Geometry.
-
Produces one interleaved stream containing separated Multichannel Speech Streams and Audio Scene Geometry.
-
This standard specifies workflow and interfaces between AIMs for en-hanced audio conference experience from speech detection and separation to noise cancellation and audio object packaging. Receiver can directly reach dominant denoised speech at the other side in the audioconference call. As an immersive audio alternative, receiving the packaged separated and denoised speech which are outputs from the speaker side can be used to post-produce the same event as the receiver is spatially inside in the event.
While immersive audio applications are growing in popularity, the hardware advances in microphone arrays, i.e., increasing the number of microphones, make a broad range of AI techniques available to acoustic scene analysis.
The current specification is limited to a minimum number of 4 microphones placed in a tetrahedral array shape. The next objective is to decrease the minimum necessary number of microphones without degrading the separation performance.
13.8Company performance prediction
The fact that one of the most requested figures in the labour market is the data scientist’s role shows that data analysis is increasingly assuming the role of an essential activity for companies, financial institutions and government administrations. The sub-phases of risk assessment are currently based on data management, and analysis and data collection can account for 75% of Risk Management & Business Continuity processes. Data analysis is also necessary to monitor the business situation and make more informed decisions for future strategies. At the same time, regulators require ever greater transparency from an analysis of a large amount of data. This is a highly time-consuming activity, and it is not always possible to obtain the most relevant information from large amounts of data.
With the Company Performance Prediction (CPP) use case of the MPAI Compression and Understanding of Industrial Data (MPAI-CUI) standard, MPAI provides initial answers to these increasingly pressing needs by introducing a versatile AI-based standard able to offer the most accurate predictions possible in both the short and medium term. Solutions characterised by a new process of tuning ML methods to improve performance because if we want good education for humans, we should do good training for AI.
CUI-CPP is the technical specification designed as a decision support system to solve these problems in the financial field targeting the assessment of a company from its financial, governance and risk data. ML and inference algorithms make it possible to predict a company’s performance for a time horizon up to 60 months.
The CUI-CPP workflow depicted in Figure 22 shows that Company Perfor-mance Prediction is captured by the following three measures:
-
Default Probability: the probability of company default (e.g., crisis, bankruptcy) dependent on financial and governance features in a specified number of future months.
-
Organisational Model Index: the adequacy of the organisational model (e.g., board of directors, shareholders, familiarity, conflicts of interest).
-
Business Discontinuity Probability: the probability that company operations are interrupted for a duration less than 2% of the prediction horizon.
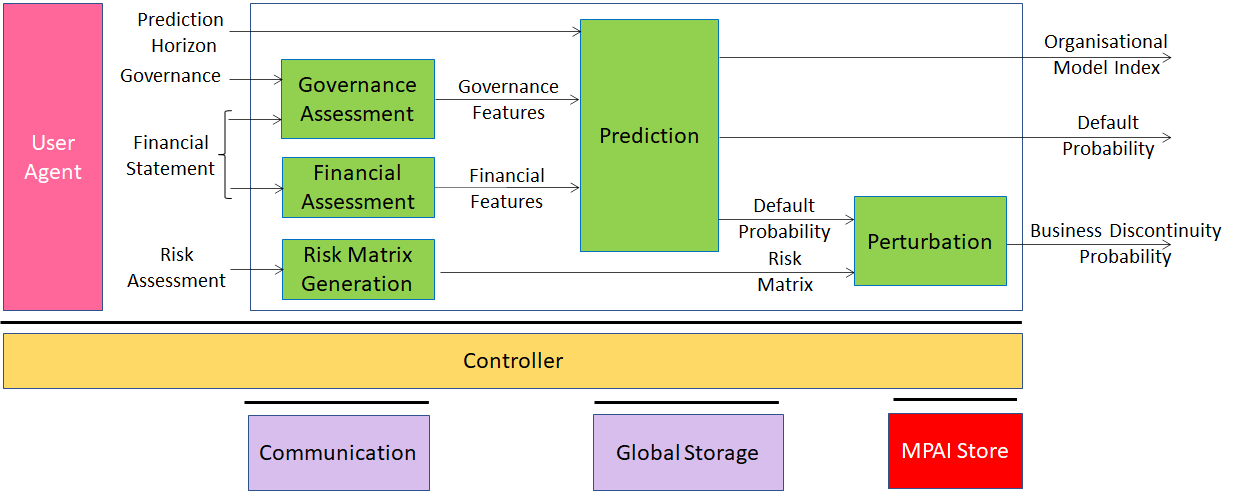
Figure 22 – Company performance prediction
MPAI-CUI can be used for several purposes:
-
To support the company’s board in deploying efficient strategies by analysing the company financial performance and identifying possible evidence of crisis or risk of bankruptcy years in advance. The board can take actions to avoid these situations, conduct what-if analysis, and devise efficient strategies.
-
To assess the financial health of companies applying for funds. A financial institution receiving a request for funds, can access the company’s financial and organisational data and assess, as well as predict future performance. Financial institutions can make the right decision whether funding the company or not, based on a broader vision of its situation.
-
To assess public policies and scenarios of public interventions in advance of their application, as well as to identify proactive actions to increase resiliency of countries. An example of this use is reported in [31] where the socio-economic effects of financial instruments on the performance and business continuity of the beneficiary companies shows how AI can support public decision-makers in creating and deploying regional policies.
In a nutshell, CUI-CPP is a powerful and extensible way to predict the performance, simplify analyses and increase efficiency of a company.
| <–Divide and conquer | Structure of MPAI standards–> |