| <–Audio for humans | Data for machines–> |
| 9.1 | DP-based video coding |
| 9.2 | AI-based video coding |
| 9.3 | Point clouds |
| 9.4 | Video for machines |
9.1 Data Processing-based video coding
Because of the limited bandwidth available for transmission and storage, we would not have reached the present state of digital television development without the series of efficient MPEG video codecs. In the last 30 years, they have been universally adopted by different product sectors. Standard codecs offer a stable environment for broadcasters and manufactures to develop their systems and services.
Why do we need compression? Digital HD 50 frame per second for studio requires a bitrate of 3 Gbit/s for, and 4K 50 frame per second requires 12 Gbit/s. Storing a 2-hour movie requires a capacity of 21 TBytes and 84 TBytes, respectively. Capacity of practically used terrestrial channel is in the range of 13 to 30 Mbit/s, and 40 Mbit/s for satellite and cable. In Italy, where digital standard definition television is typically transmitted at 2-5 Mbit/s on 12 Mbit/s channels, some four to five programmes can be broadcasted within an 8 MHz UHF channel. To achieve this, a bitrate, reduction between the high-quality studio and broadcasted video, is required.
Fortunately, video frames contain lots of redundant information, which can be exploited to reduce the bitrate. Since video coding studies began in the 1960s, various coding techniques have been explored and incorporated into compression standards starting from the early 1980s. The principal technique is the subdivision of a picture into square blocks of pixels. When the average number of bits/pixel is low, blocks may appear in a coded picture. Over the years, many algorithms have been developed to compensate for this effect.
The MPEG-2 standard, approved in 1994 after extensive research and participant market testing, continues to be one of the most widely used compression technologies in digital video.
Since then, video compression has used a block-based hybrid video codec, which basically uses the following processing elements (Figure 9):
-
Exploit the spatial and temporal redundancies (Intra and Inter coding)
-
Create a residual signal between the current video frame and a predicted frame
-
Transform the residual signal into the frequency domain using the discrete cosine transform (Residual Coding)
-
Quantise the frequency domain coefficients to maximise the zero run-lengths.
-
Encode the quantised transform coefficients with an entropy encoder (Entropy Coding)
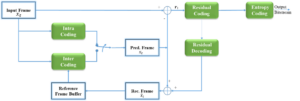
Figure 9 – Hybrid video coding scheme
In 1998 and 1999, two video coding standards were published: H.263 and MPEG-4 Visual. The MPEG-4 Advanced Video Coding (AVC) standard includes various video compression algorithms, e.g., coding structure and intra prediction. Such coding tools are still being used today. AVC is perhaps best known as the video coding format for Blu-ray discs, streaming Internet sources, HDTV broadcasts over terrestrial (ATSC, ISDB-T, DVB-T or DVB-T2), cable (DVB-C), and satellite (DVB-S and DVB-S2) systems.
Increased precision or adaptation of existing coding tools and the introduction of new coding tools has led to the High-Efficiency Video Coding (HEVC) standard, approved in 2013. The standard could rely the increased computational resources made available by the increased capabilities of semiconductor technologies, as a consequence of the Moore’s law (a doubling of processing power every 18 months).
The same applies to the latest Versatile Video Coding (VVC) standard that offers a significant compression improvement over HEVC, although it uses a similar design methodology (i.e., by increasing precision and adaptation relative to HEVC).
To grasp the ideas behind the evolution of codecs it is necessary to understand the video coding standardisation process. Compression algorithms have undergone continuous improvements or refinements. These have been incorporated in MPEG standards, after competitive assessment of their visual quality merits. However, MPEG only standardised the bitstream format and the decoding process. This enables the industry to introduce a sequence of refinements at the encoder side, without altering the bitstream syntax. This enables service providers to offer a better service without replacing end-users’ equipment, i.e., set-top boxes and digital television sets.
Usually, the improvement rate declines as a negative exponential: the most gains are usually made in the first years, whereas later improvements do not significantly reduce the bitrate, approaching an asymptote. Before the asymptote is reached, a new codec is standardised and introduced into the market. At this point, there is a quantum-leap gain in compression efficiency because the new codec can take advantage of all the existing improvements as well as incorporating new concepts into its design from research.
Some codecs are application-specific, and some are designed to have wide use. MPEG-1 was intended for interactive video storage on CD-ROM. MPEG-2 was developed for video broadcast and DVD and eventually used for television studio processing. H.263 was intended for video conferencing. MPEG-4 Visual addressed a broad range of applications, including video animation and coding of multiple objects within a video frame. With its higher compression, HEVC addresses Ultra High Definition (4K), High Dynamic Range and Wide Colour Gamut. Versatile Video Coding was developed for 8K, 360 videos, screen content coding, adaptive resolution changes, and independent sub-pictures.
The principal reason for retaining a video codec is the need to sustain the economic life of consumer devices and video services. In the case of national television broadcasting, socio-political factors come into play, along with backwards-compatibility constraints.
The market today is still dominated by the AVC codec, approved in 2003, due to its broad decoder support and accessible licensing scheme. HEVC, approved in 2013, was expected to supersede its predecessor AVC, as it provides an improved compression performance of ~50% for comparable perceptual video quality. Its adoption, however, has been slow because of unclear royalty schemes that some say are outdated. Besides three patent pools (MPEG LA, HEVC Advance, Velos Media), there are several other Intellectual Property (IP) holders who are not members of any of them.
The MPEG-5 Essential Video Coding (EVC) standard tried to mitigate the problem. The standard has two profiles, one making use of 20+ year-old technologies. The performance of the other profile is close to the performance of HEVC. A reduced number of entities are reported to hold patents in MPEG-5 EVC and 3 have declared they would publish their licences within 2 years after approval of the standard.
This complex situation has undermined a widespread adoption of HEVC that is now being challenged by other technologies promising better performance and/or royalty free access to the compression technology. The fate of VVC is still unclear; a licence is yet to be announced.
9.2AI-based video coding
The first video coding standard (H.120) came into being 40 years ago. Since then, a long series of video coding standards have been investigated and released. In addition to the MPEG standards mentioned, AVS, AVS2, and AVS3 continue to improve coding efficiency by introducing more adaptive coding tools, as well as offering more flexible features to enlarge the selection of rate-distortion candidates. However, almost all the designs come from suitably improved prior models.
Recently, deep learning has consistently made breakthroughs in the fields of computer vision, language processing and multimedia signal processing. There is also a large amount of deep network-based explorations in the context of video coding, especially end-to-end learned approaches.
Figure 10 shows the historical development of neural NN-based image and video compression approaches. The NN-based image roadmap is given by upper part and the video coding roadmap in the lower part, respectively.
Apparently, NN-based image compression synchronises with neural network research trends. A NN-based image compression algorithm was proposed in the late 1980s, corresponding to the time when NN back-propagation learning was proposed. Generative models for video coding were first used for high compression. Since 2016, however, a flurry of neural models for the hybrid video coding framework can be observed, where each module can also be optimised by data-trained deep networks. In addition, the end-to-end video compression solutions followed after the NN-based image compression methods began to surpass the coding efficiency of conventional codecs.
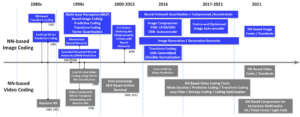
Figure 10 – Evolution of AI-based image and video coding
It has been shown that significant coding gains can be obtained with deep learning-based models in the hybrid coding framework. If every single module were realised with deep networks, then a fully deep neural network-based coding framework, called End-to-End Video Coding (EEV), can be realised. A typical EEV model is depicted in Figure 11, which is very similar to the well-known hybrid model. The main difference is that such a framework is an end-to-end trainable and fully parametrised NN. Some expect that the EEV equipped with neural networks will signal the beginning of a new age for video compression. Moreover, the end-to-end optimisation can overcome the problem of local optimisation in hybrid coding frameworks.
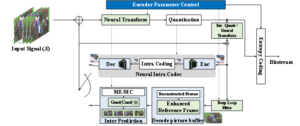
Figure 11 – A typical EEV framework
Figure 12 plots published works in this area from recent years showing that EEV is a fresh research area.
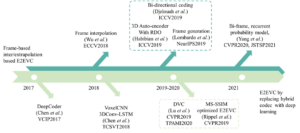
Figure 12 – Recent progress of EEV
In 2017, the first fully neural network based EEV model was proposed by Chen et al. [11]. Much like had happened for deep image coding, in the following years many optimisation and refinement models were proposed. Currently, state-of-the-art EEV models have similar or slightly better performance than the x265 codec, an HEVC open-source implementation. Based on this coding performance, however, it seems that much effort needs to be allocated to further boost EEV’s coding efficiency, if the conventional video coding standards is to be surpassed. Interested readers might refer to the papers identified in the figure where two main categories of works are indicated: frame-based inter/extrapolation and hybrid codec replacement with deep networks.
9.3Point clouds
Lidars provide the distance between a sensor and a point on a surface by measuring the time taken by the light reflected by the surface to return to the receiver. The operation wavelenghth is in the µm range – ultraviolet, visible, or near infrared light.
A Point Cloud is a set of individual 3D points, each point having a 3D position but also being able to contain some other attributes such as RGB attributes, surface normal, etc. 3D point cloud data can be applied to many fields, such as cultural heritage, immersive videos, navigation, virtual reality (VR) /augmented reality (AR) etc. Because applications are different, two different standards exists. If the points are dense, Video-based Point Cloud Compression (V-PCC) is recommended. If less so Graphic-based Point Cloud Compression (G-PCC) is recommended. The algorithms in both standards are lossy, scalable, progressive and support random access to subsets of the point cloud.
V-PCC projects the 3D space into a set of 2D planes. The algorithm generates 3D surface segments by dividing the point cloud into a number of connected regions, called 3D patches. Each 3D patch is projected independently into a 2D patch. The resulting patches are grouped into 2D frames and encoded by using traditional video technologies.
G-PCC addresses directly the 3D space to create the predictors (with algorithms that resemble the intra prediction in video coding). To achieve that, G-PCC utilizes data structures that describe the point locations in a 3D space. Moreover, the points have an internal integer-based value, converted from a floating point value representation.
Currently V-PCC offers a compression of ~125:1, a dynamic point cloud of 1 million points can be encoded at 8 Mbit/s with good perceptual quality. G-PCC provides a compression ratio up to 10:1 and acceptable quality lossy coding of ratio up to 35:1
9.4Video for machines
After MPEG-2 was completed and when MPEG-4 was being developed, in 1996, MPEG started addressing the problem of video coding for uses other than efficient compression for transmission and storage. The scope of the MPEG-7 standard is well represented by Figure 13 where a human looking for a content item – image, video, but audio as well – queries a machine which knows about content items through their features.
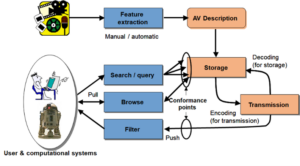
Figure 13 – The MPEG-7 standard
MPEG-7 developed a large number of Descriptors. A short list is: Color-Structure Descriptor, Texture Descriptor, Edge Histogram, Shape Descriptors, Camera Motion, Motion Trajectory, Motion Activity, Region Locator, Spatio-Temporal Locator. The descriptors have a human understandable semantics and a precise syntax.
Video key information, i.e., visual features, can be extracted, represented and compressed in a compact form. In particular, it is possible to transmit the feature stream in lieu of the video signal stream using significantly less data than the compressed video itself. Compact descriptors for visual search (CDVS) were standardised in Sep. 2015 and compact descriptors for video analysis (CDVA) in July 2019. The standardized bitstream syntax of compact feature descriptors enable interoperability for efficient image/video retrieval and analysis. CDVS is based on hand-crafted local and global descriptors, designed to represent the visual characteristics of images. CDVA is based on the deep learning features, adopted to further improve the video analysis performance.
In 2018 MPEG launched the Video Coding for Machines investigation. The main motivation was the large number of video content generated that is not expected to be watched by humans, if not occasionally, but is monitored by machines. The new type of video coding seeks to enable a machine to process the features received in compressed form without significant degradation.
| <–Audio for humans | Data for machines–> |