<- References Go to ToC Composite AI Modules ->
Human and Machine Communication includes the Communicating Entities in Context (HMC-CEC) Use Case specified in the following six chapters.
1 Functions
2 Reference Model
3 Input/Output Data
4 Functions of AI Modules
5 Input/Output Data of AI Modules
6 AIW, AIMs, and JSON Metadata
1. Functions
The Communicating Entities in Context (HMC-CEC) Use Case involves 1) a human in a real audio-visual scene or the Digital Human representation of a Machine in an Audio-Visual Scene and 2) another human in a real audio-visual scene or the Digital Human representation of a Machine in an Audio-Visual Scene.
Communication is enabled by a Machine that:
- Receives Communication Items from other Machines.
- Captures:
- Audio-visual scenes containing communicating humans.
- Audio-Visual Scenes containing Digital Humans.
- Understands the information emitted by the Entity including its Context.
- Produces a reaction to the information received in the form of .
- Communication Item for use by other Machines.
- Audio-Visual Scenes containing a representation of itself for use by humans and other Machines.
- Renders the Audio-Visual Scene.
MPAI-HMC assumes that:
- Input Audio is Multichannel Audio and Input Visual is visual information in a format suitable for processing by the Visual Scene Description AIM.
- Output Audio and Output Visual convey audio and visual information for rendering by the Audio-Visual Rendering AIM.
- The real space where the human is located is digitally represented as an Audio-Visual Scene that may include other humans and generic objects.
- The Virtual Space containing a Digitised or Virtual Human (collectively “Digital Humans”) and/or its Audio components is represented as an Audio, Visual, or Audio-Visual Scene that may include other Digital Humans and generic Objects.
- The Machine can:
- Understand the semantics of the communicated information at different layers of depth.
- Produce a multimodal response expected to be congruent with the received information.
- Represent itself as a speaking humanoid immersed in an Audio-Visual Scene.
- Convert the semantics of the Text, Speech, Face, and Gesture issued by an Entity in a Context to a form that is compatible with the Context of another Entity.
An AI Module is specified only by its Functions and Interfaces. Implementers are free to use their preferred technologies to achieve the Functions providing the features while respecting the constraints of the Interfaces.
Annex 2 – Usage Scenarios offers a collection of example applications enabled by HMC-CEC.
2 Reference Model
Figure 1 depicts the Reference Model of the Communicating Entities in Context (HMC-CEC) Use Case implemented as an AI Workflow (AIW) that includes AI Modules (AIM) per Technical Specification: AI Framework (MPAI-AIF). Three out of six AIMs in Figure 1 (Audio-Visual Scene Description, Entity Context Understanding, and Personal Status Display) are Composite AIMs, i.e., they include interconnected AIMs. Basic information on MPAI-AIF is provided here.
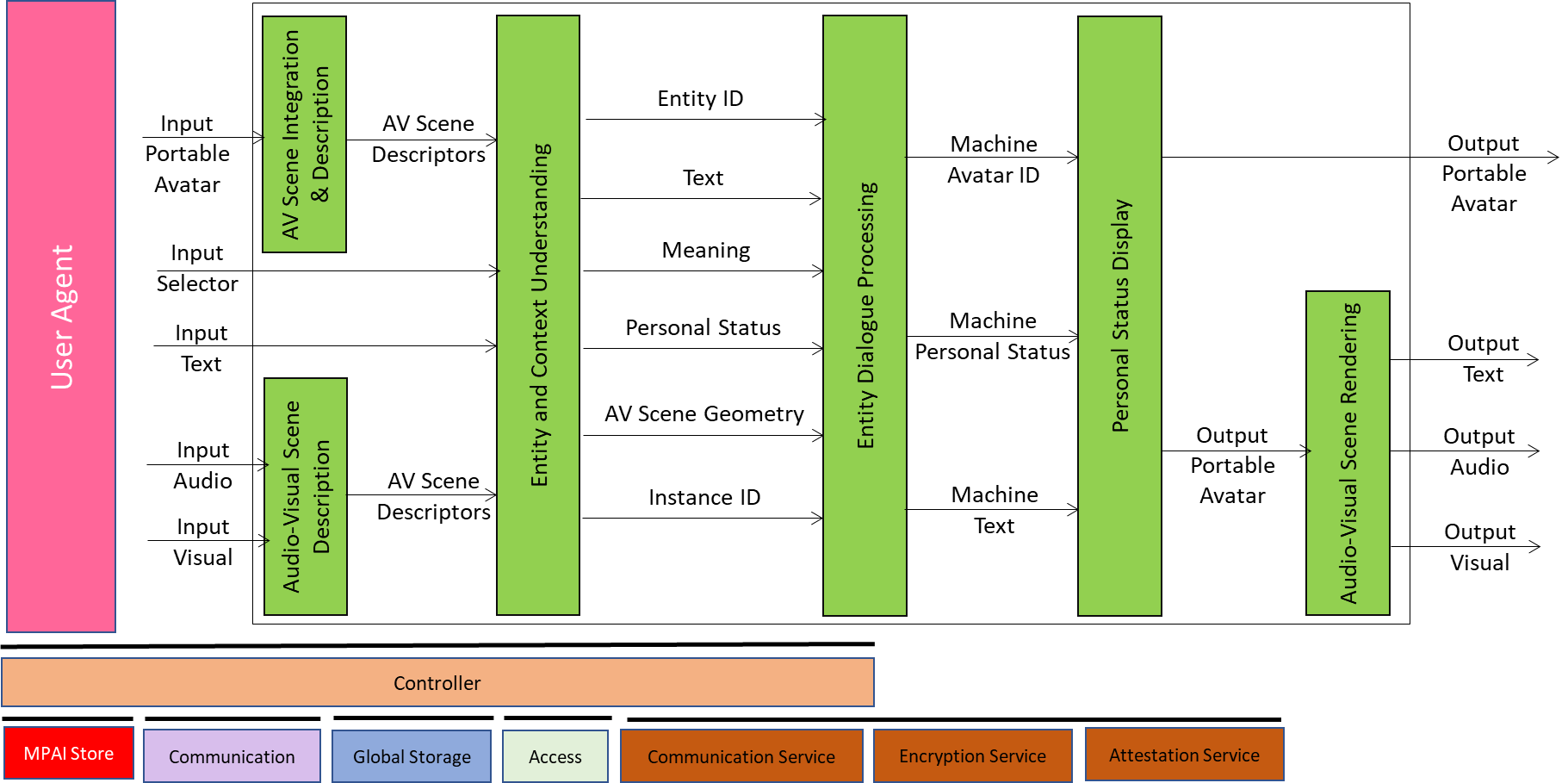
Figure 1 – Human-Machine Communication AIW
Note that:
- Words beginning with a capital are defined in Definitions, Words beginning with a small letter have the common meaning.
- The Input Selector enables the Entity to inform the Machine through the Entity and Context Understanding AIM about use of Text vs. Speech, Language Preferences, and Selected Language in translation.
- The Machine captures the information emitted by the Entity and its Context through Input Text, Input Speech, and Input Visual.
- The Input Portable Avatar is the Communication Item emitted by a communicating Machine.
- The Audio-Visual Scene Descriptors produced by the Audio-Visual Scene Description and Audio-Visual Scene Integration and Description AIMs are digital representations of a real audio-visual scene or a Virtual Audio-Visual Scene.
- To facilitate identification, AIMs are labelled by three letters indicating the three letters of the Technical Specification that specifies it followed by a hyphen “-” followed by three letters uniquely identifying the AIM defined by that Technical Specification. For instance, Portable Avatar Demultiplexing is indicated as PAF-PDX where PAF refers to Technical Specification: Portable Avatar Format (MPAI-PAF) and PDX refers to the Portable Avatar Demultiplexing AIM specified by MPAI-PAF.
3 Input/Output Data of AIW
The HMC-CEC AIW is specified by its Functions, its Input and Output Data and its AIM topology. Table 1 specifies the Input and Output Data of HMC-CEC. The topology is specified by Reference Model. Each Input and Output Data of HMC-CEC is linked to its definition or specification. HMC-CEC does likewise for the Input/Output Data of each AIM.
Table 1 – Input/Output Data of MPAI-HMC
| Input | Description |
| Portable Avatar | A Communication Item emitted by the communicating Entity. |
| Input Selector
|
Selector containing data that determines: 1. Whether the communicating Entity uses Speech or Text as input. 2. Which language is used as input. 3. The target Language in translation. |
| Input Text | Text Object generated by the communicating Entity as information additional to or in lieu of Speech Object. |
| Input Audio | The audio scene captured by the Machine. |
| Input Visual | The visual scene captured by the Machine. |
| Output | Description |
| Portable Avatar | The Communication Item produced by the Machine. |
| Output Audio | The rendered audio corresponding to the Audio in the Communication Item. |
| Output Visual | The rendered visual corresponding to the visual in the Communication Item. |
| Output Text | The Text contained in a Communication Item or associated with Output Audio and Output Visual. |
4 Functions of AI Modules
Table 2 gives the functions of HMC-CEC AIMs.
Table 2 – Functions of AI Modules
| AIM | Functions |
| Audio-Visual Scene Integration and Description | Adds Avatar to Audio-Visual Scene in Portable Avatar providing Audio-Visual Scene Descriptors. |
| Audio-Visual Scene Description | Provides Audio-Visual Scene Descriptors. |
| Entity Context Understanding | Understands the information emitted by the Entity and its Context. |
| Entity Dialogue Processing | Produces Text and Personal Status of Machine in response to inputs. |
| Personal Status Display | Produces Portable Avatar. |
| Audio-Visual Scene Rendering | Renders the content of the Portable Avatar. |
5 Input/Output Data of AI Modules
Table 3 gives the I/O Data of the AIMs of HMC-CEC.
Table 3 – Input/Output Data of AI Modules
| AIM | Receives | Produces |
| Audio-Visual Scene Integration and Description | Input Portable Avatar | Audio-Visual Scene Descriptors |
| Audio-Visual Scene Description | Input Audio Input Visual |
Audio-Visual Scene Descriptors |
| Entity Context Understanding | Audio-Visual Scene Descriptors Input Selector Input Text |
Audio-Visual Scene Geometry Personal Status Entity ID Text Meaning Instance Identifier |
| Entity Dialogue Processing | Audio-Visual Scene Geometry Personal Status Entity ID Text Meaning Instance Identifier |
Machine Personal Status Machine Avatar ID Machine Text |
| Personal Status Display | Machine Personal Status Machine Avatar ID Machine Text |
Output Portable Avatar |
| Audio-Visual Scene Rendering | Output Portable Avatar | Output Text Output Audio Input Visual |
6 AIW, AIMs, and JSON Metadata
Table 4 – AIW, AIMs, and JSON Metadata