MPAI calls for a new generation of company performance prediction technologies
The 51st MPAI General Assembly has decide to develop a new version V2.0 of Compression and Understanding of Financial Data (MPAI-CUI) – Company Performance Prediction (CUI-CPP) and issued a Call for Technologies to acquire relevant technologies. Register to attend online event where the Call will be presented on 2025/01/08 T15:00 UTC.
Compression and Understanding of Industrial Data (MPAI-CUI) was one of the first (2021) MPAI standards. The MPAI-CUI V1.0 Company Performance Prediction Use Case was based on the notion that the future of a company largely depends on structure, financial state, and risks it may face in the future. The solution used to address the complex task of creating a standard to predict the future of a company using such variables was successfully achieved was based on:
- Governance Data, Financial Data, and Risk Assessment Data.
- Conversion of Governance Data and Financial Data into Descriptors.
- Conversion of Risk Assessment Data into a Risk Matrix.
- Passing the Governance and Financial Descriptors to an Organisation Assessment and Default Prediction neural network.
- Perturbing the Default Probability from the neural network with the Risk Matrix to obtain the Discontinuity Prediction.
Governance Descriptors used as input to the neural network were: #Stakeholder Individuals, #Stakeholder Companies, Shareholder Share, Shareholders Gender, Decision-Makers Gender, #Decision-Makers, Members of the Revision And Advisory Board, Presence Of The Advisory Company, #Decision-Makers By The Same Family, Company Phase (Age).
Financial Descriptors used as input to the neural network were: Revenues, EBITDA Margin, EBITDA, Quick Ratio, Current Ratio, Net Working Capital, Net Financial Position, Net Short-Term Assets, Shareholder Funds-Fixed Assets, Long-Term Liability Ratio, Coverage Of Fixed Assets, Amortisation Rate, Debt On Sales, Interest Coverage Ratio, Average Stock Turnover, Stock Coverage Days, Return On Investments (ROI), Return On Assets (ROA), Return On Sales (ROS), Return On Equity (ROE), Cash Flow, Interest On Sales, Type Of Financial Statement.
Risk Matrix included the following characteristics: Occurrence (3 values), Business Impact (3 values), Gravity (5 values), Risk retention (portion of the risk that the Company decides to retain).
The Governance and Financial Descriptors together with the Prediction Horizon fed to Neural Network provided an Organisational Model Index and a Default Probability. Default Probability and Risk Matrix fed to a Prediction Result Perturbation AIM which perturbed the Default Probability and produced the Business Discontinuity Probability.
Figure 1 depicts the AI Workflow that performs as described above.
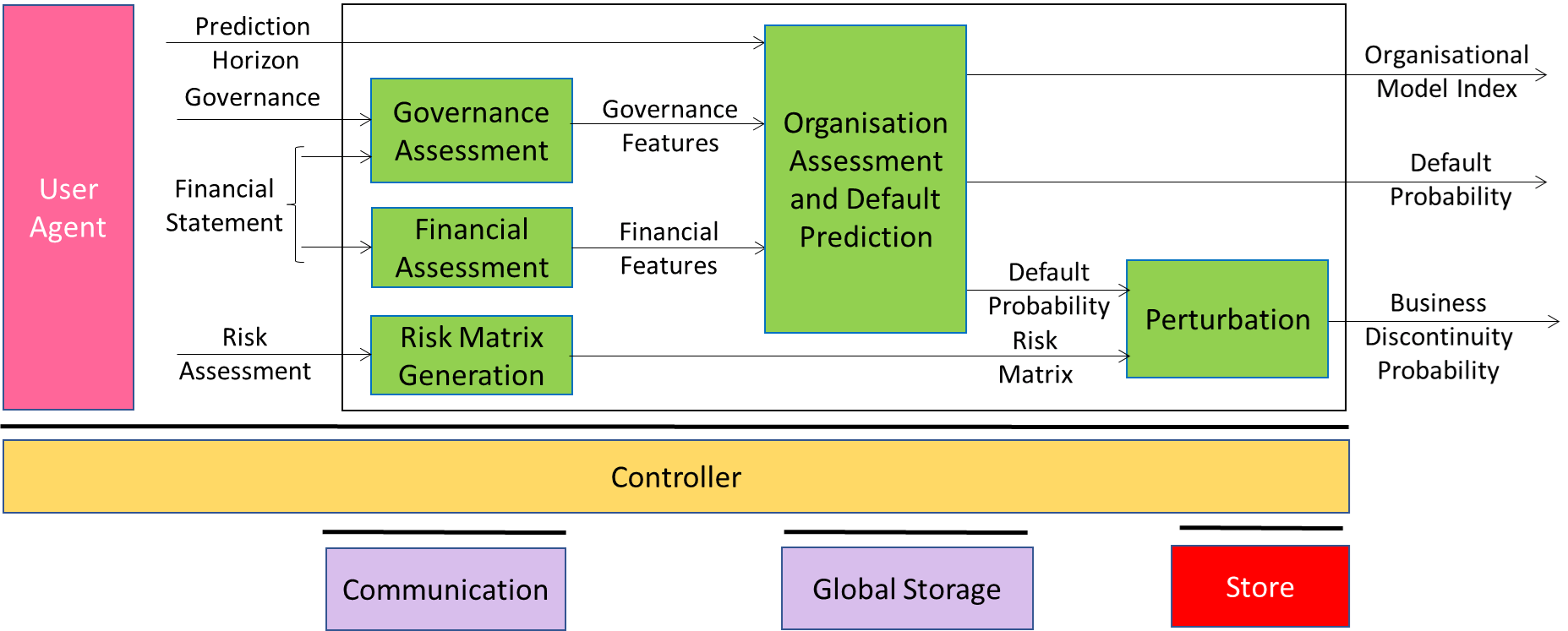
Figure 1 – The Company Performance Prediction AI Workflow of MPAI-CUI V1.1
At the 51st General Assembly (MPAI-51) MPAI issued a Call for Technologies for substantially more ambitious goal for MPAI-CUI V2.0 because it Company performance prediction targets:
- A more precise identification of Cyber, Digitisation, Climate, and Business risks.
- A definition of risks to be organised as follows:
- Risk name, Risk type: (cyber, etc.),
- Target regulation,
- Vector of inputs including, e.g. for Cyber Risks:
- Name of input: IP address, Denial of service;
- Time: time the attack was detected;
- Source: provider of input vector; Type: image, text, category, etc.;
- Value: depends on type.
With this additional information, the task is to define a (set of) neural network(s) that receive(s) Risk Data in addition to Governance and Financial Descriptors. The Assessment and Prediction network of Figure 2 are not only numbers but Descriptors that include index or probability but also information on which input elements have more influence on index and probabilities.
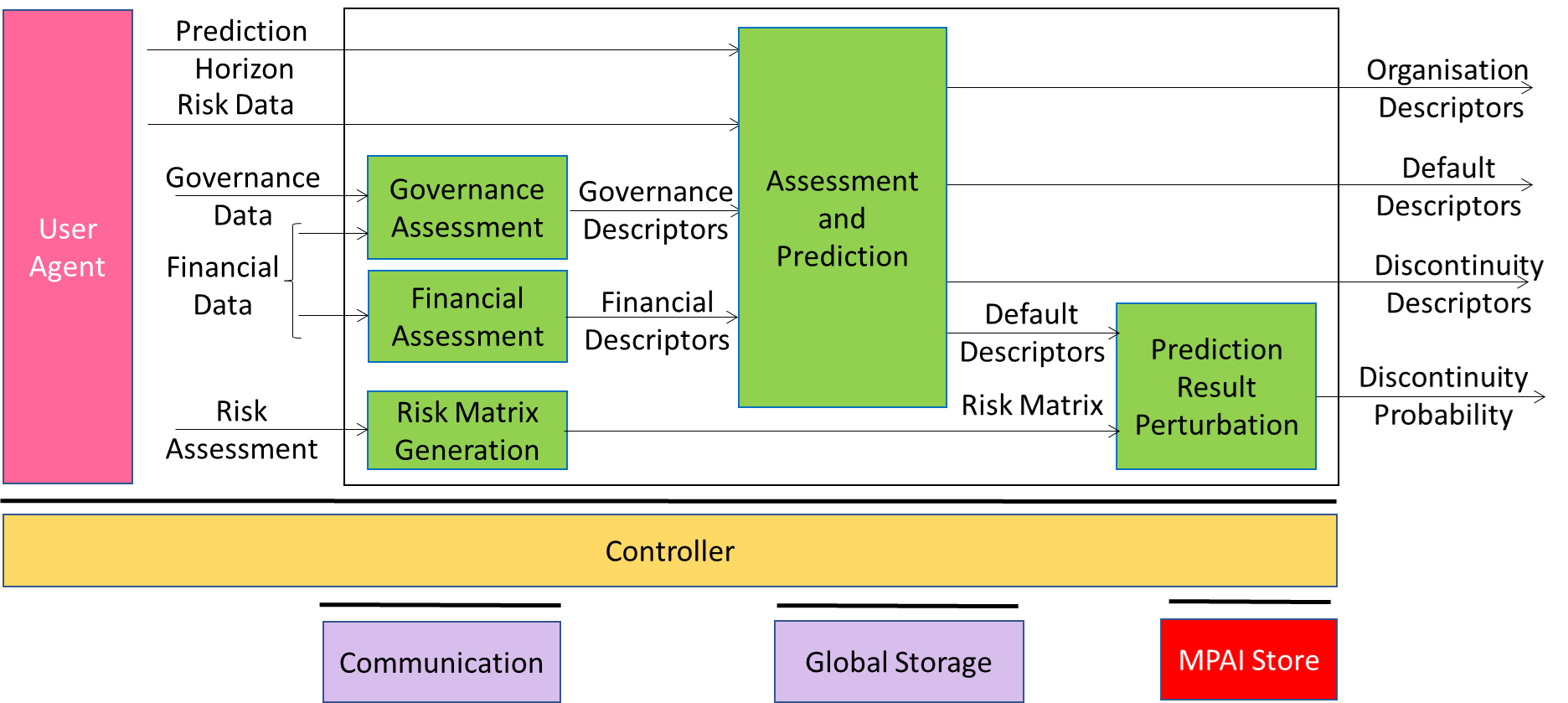
Figure 2 – The Company Performance Prediction AI Workflow of MPAI-CUI V1.1
Risk Assessment and Risk Matrix are used when sufficient data are not available to train the Neural Network or when the Neural Network may not be used because it does not comply with relevant regulations.
The Call for Technologies is directed to all parties having rights to technologies satisfying the Use Cases and Functional Requirements and the Framework Licence of the planned Technical Specification MPAI-CUI V2.0 are invited to respond to the Call for Technologies, preferably using the Template for Responses. Submissions received by 2024/02/11 will be assessed and considered for use in the development of said MPAI-CUI Technical Specification.